Ensemble Methods in Machine Learning: Bagging & Subagging


In this blog, we will explore the Bagging algorithm and a computational more efficient variant thereof, Subagging. With minor modifications, these algorithms are also known as Random Forest and are widely applied here at STATWORX, in industry and academia.
Almost all statistical prediction and learning problems encounter a bias-variance tradeoff. This is particularly pronounced for so-called unstable predictors. While yielding low biased estimates due to flexible adaption to the data, those kind of predictors react very sensitive to small changes in the underlying dataset and have hence high variance. A common example are Regression Tree predictors.
Bagging bypasses this tradeoff by reducing the variance of the unstable predictor while leaving its bias mostly unaffected.
Method
In particular, Bagging uses repeated bootstrap sampling to construct multiple versions of the same prediction model (e.g. Regression Trees) and averages over the resulting predictions.
Let's see how Bagging works in detail:
- Construct a bootstrap sample $(y_{i}^{*}, mathbf{x_{i}^{*}}) :(i = 1, dots , n)$ (with replacement) of the original i.i.d. data at hand $ (y_{i}, mathbf{x_{i}}) : (i = 1, dots , n)$.
- Fit a Regression Tree to the bootstrap sample - we will denote the tree predictor by $hat{theta}_{n}^{*}(mathbf{x})$.
- Repeat Steps one and two $B$ many times and calculate $ frac{1}{B}sum_{b=1}^{B}hat{theta}_{n, b}^{*}(mathbf{x})$ .
OK - so let us take a glimpse into the construction phase: We draw in total $B$ different bootstrap samples simultaneously from the original data. Then to each of those samples, a tree is fitted and the (in-sample) fitted values are averaged in Step 3 yielding the Bagged predictor.
The variance-reduction happens in Step 3. To see this, consider the following toy example.
Let $X_1, dots, X_n$ be i.i.d. random variables with $mu = E[X_1]$ and $sigma^2 = Var[X_1]$ and let $bar{X}= frac{1}{n}sum_{i=1}^{n}X_{i}$. Easy re-formulations show that
- $Var[bar{X}]=frac{sigma^2}{n} leq sigma^2$
- $E[bar{X}]=mu$
We observe that indeed the variance of the mean is weakly smaller than for the individual random variables while the sample mean is unbiased.
It is widely discussed in the literature why Bagging works and it remains an open research question. Bühlmann and Yu (2002) propose a subsampling variant of Bagging, called Subagging, which is more traceable from a theoretical point of view.
In particular, Bühlmann and Yu (2002) replace the bootstrap procedure of Bagging by subsampling without replacement. Essentially, we are only changing Step 1 of our Bagging algorithm by randomly drawing $m$ times without replacement from our original data with $m < n$ and get hence a subset of size $m$. With this variant at hand, it is possible to state upper bounds for the variance and mean squared error of the predictor given an appropriate choice of the subsample size $m$.
Simulation Set-Up
As the theory is a little bit cumbersome and involves knowledge in real analysis, we simulate the main findings of Bühlmann and Yu (2002).
Let's compare the mean-squared prediction error (MSPE) of the Regression Tree, Bagged and Subagged predictor and illustrate the theory part a little bit more.
In order to do this, we consider the following model
$$y_{i} = f(mathbf{x}_{i}) + epsilon_{i}$$
where $f(mathbf{x}_{i})$ is the regression function, $ mathbf{x}_{i} sim U^{10}[0,1]$ is the design matrix generated from a uniform distribution and $epsilon_{i}sim N(0,1)$ is the error term ($forall i = 1, dots, n$).
For the true data-generating process (DGP), we consider the following model which is quite frequently used in the machine learning literature and termed "Friedman #1"-model:
$$f(mathbf{x}) = 10 sin(pi x^{(1)} x^{(2)}) + 20(x^{(3)} - frac{1}{2})^{2} + 10 x^{(4)} + 5 x^{(5)}$$
where $ mathbf{x}^{(j)}$ is the $j$-th column of the design matrix $ mathbf{x}$ (for $1 leq j leq 10$).
As you can see, this model is highly non-linear - Regression Tree models shall therefore be appropriate to approximate our DGP.
To evaluate the prediction performance of Bagging and Subagging predictors we conduct a Monte Carlo simulation in Python.
We first import the relevant packages.
<span class="hljs-keyword"><span class="hljs-keyword">import</span></span> numpy <span class="hljs-keyword"><span class="hljs-keyword">as</span></span> np
<span class="hljs-keyword"><span class="hljs-keyword">import</span></span> sklearn.model_selection
<span class="hljs-keyword"><span class="hljs-keyword">import</span></span> sklearn.ensemble
<span class="hljs-keyword"><span class="hljs-keyword">import</span></span> simulation_class
<span class="hljs-keyword"><span class="hljs-keyword">import</span></span> math
<span class="hljs-keyword"><span class="hljs-keyword">from</span></span> sklearn.metrics <span class="hljs-keyword"><span class="hljs-keyword">import</span></span> mean_squared_error
<span class="hljs-keyword"><span class="hljs-keyword">from</span></span> sklearn.tree <span class="hljs-keyword"><span class="hljs-keyword">import</span></span> DecisionTreeRegressor
The module simulation_class is a user-specified class that we will not discuss in this blog post but in a subsequent one.
Further, we specify the simulation set-up:
<span class="hljs-comment"><span class="hljs-comment"># Number of regressors</span></span>
n_reg = <span class="hljs-number"><span class="hljs-number">10</span></span>
<span class="hljs-comment"><span class="hljs-comment"># Observations</span></span>
n_obs = <span class="hljs-number"><span class="hljs-number">500</span></span>
<span class="hljs-comment"><span class="hljs-comment"># Simulation runs</span></span>
n_sim = <span class="hljs-number"><span class="hljs-number">50</span></span>
<span class="hljs-comment"><span class="hljs-comment"># Number of trees, i.e. number of bootstrap samples (Step 1)</span></span>
n_tree = <span class="hljs-number"><span class="hljs-number">50</span></span>
<span class="hljs-comment"><span class="hljs-comment"># Error Variance</span></span>
sigma = <span class="hljs-number"><span class="hljs-number">1</span></span>
<span class="hljs-comment"><span class="hljs-comment"># Grid for subsample size</span></span>
start_grid = <span class="hljs-number"><span class="hljs-number">0.1</span></span>
end_grid = <span class="hljs-number"><span class="hljs-number">1</span></span>
n_grid = <span class="hljs-number"><span class="hljs-number">100</span></span>
grid_range = np.linspace(start_grid, end_grid, num = n_grid)
Below we will explain in more detail what we need the grid specification.
To store our simulation results we set up containers.
<span class="hljs-comment"><span class="hljs-comment"># Container Set-up</span></span>
mse_temp_bagging = np.empty(shape = (n_obs, n_sim))
mse_temp_subagging = np.empty(shape = (n_obs, n_sim))
y_predict_bagging = np.empty(shape = (n_obs, n_sim))
y_predict_subagging = np.empty(shape = (n_obs, n_sim))
mse_decomp = np.empty(shape = (len(grid_range),<span class="hljs-number"><span class="hljs-number">2</span></span>))
With this initialization at hand, we generate the test and train data by the simulation_class module.
<span class="hljs-comment"><span class="hljs-comment">#Creation of Simulation-Data</span></span>
train_setup = simulation_class.simulation(n_reg = n_reg,
n_obs = n_obs,
n_sim = n_sim,
sigma = sigma,
random_seed_design = <span class="hljs-number"><span class="hljs-number">0</span></span>,
random_seed_noise = <span class="hljs-number"><span class="hljs-number">1</span></span>)
test_setup = simulation_class.simulation(n_reg = n_reg,
n_obs = n_obs,
n_sim = n_sim,
sigma = sigma,
random_seed_design = <span class="hljs-number"><span class="hljs-number">2</span></span>,
random_seed_noise = <span class="hljs-number"><span class="hljs-number">3</span></span>)
f_train = train_setup.friedman_model()
X_train, y_train = train_setup.error_term(f_train)
f_test = test_setup.friedman_model()
X_test, y_test = test_setup.error_term(f_test)
As we have generated the data for our "Friedman #1"-model we are now able to simulate the mean squared error of the Bagged predictor and Subagged predictor. In Python, both algorithms are implemented via the BaggingRegressor method of the sklearn.ensemble package. Observe that for the Subagged predictor we need to specify the parameter max_samples in the BaggingRegressor. This ensures that we can draw a subsample size $m = a cdot{} n$ with subsample fraction $a$ from the original data. Indeed, for the subsample fraction $a$ we have already specified the grid above by the variable grid_range .
<span class="hljs-comment"><span class="hljs-comment">#Subagging-Simulation</span></span>
<span class="hljs-keyword"><span class="hljs-keyword">for</span></span> index, a <span class="hljs-keyword"><span class="hljs-keyword">in</span></span> enumerate(grid_range):
<span class="hljs-keyword"><span class="hljs-keyword">for</span></span> i <span class="hljs-keyword"><span class="hljs-keyword">in</span></span> range(<span class="hljs-number"><span class="hljs-number">0</span></span>, n_sim):
<span class="hljs-comment"><span class="hljs-comment"># bagged estimator</span></span>
bagging = sklearn.ensemble.BaggingRegressor(
bootstrap = <span class="hljs-keyword"><span class="hljs-keyword">True</span></span>,
n_estimators = <span class="hljs-number"><span class="hljs-number">50</span></span>)
y_predict_bagging[:,i] = bagging.fit(
X_train,
y_train[:,i]).predict(X_test)
mse_temp_bagging[:,i] = mean_squared_error(
y_test[:,i],
y_predict_bagging[:,i])
<span class="hljs-comment"><span class="hljs-comment"># subagged estimator</span></span>
subagging = sklearn.ensemble.BaggingRegressor(
max_samples = math.ceil(a*n_obs),
bootstrap = <span class="hljs-keyword"><span class="hljs-keyword">False</span></span>,
n_estimators = <span class="hljs-number"><span class="hljs-number">50</span></span>)
y_predict_subagging[:,i] = subagging.fit(
X_train,
y_train[:,i]).predict(X_test)
mse_temp_subagging[:,i] = mean_squared_error(
y_test[:,i],
y_predict_subagging[:,i])
mse_decomp[index, <span class="hljs-number"><span class="hljs-number">1</span></span>] = np.mean(mse_temp_bagging)
mse_decomp[index, <span class="hljs-number"><span class="hljs-number">2</span></span>] = np.mean(mse_temp_subagging)
On my GitHub-Account you can find additional code which also calculates the simulated bias and variance for the fully grown tree and the Bagged tree.
Results
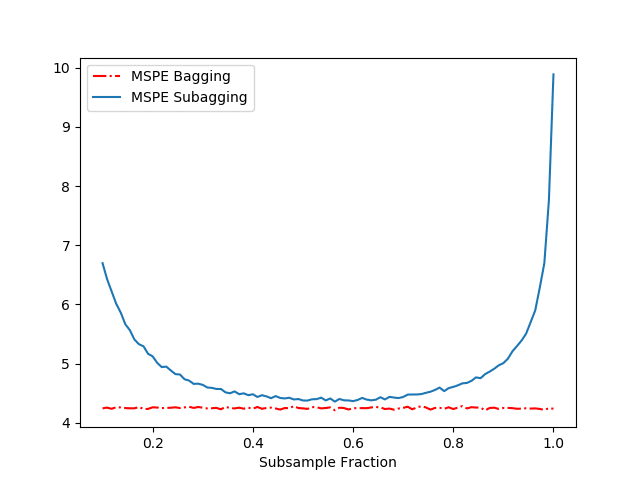
The results of our above simulation can be found in Figure 1.
Let us first compare the performance in terms of MSPE of the Regression Tree and the Bagged predictor. Table 1 shows us that Bagging drastically reduces the MSPE by decreasing the variance while almost not affecting the bias. (Recall - the mean squared prediction error is just the sum of the squared bias of the estimate, variance of the estimate and the variance of the error term (not reported).)
Table 1: Performance of fully grown tree and Bagged Predictor
Figure 1 displays the MSPE as a function of the subsample fraction $a$ for the Bagged and Subagged predictor (our above code). Together with Figure 1 and Table 1, we make several observations:
- We see that both the Bagged and Subagged predictor outperform a single tree (in terms of MSPE).
- For a subsampling fraction of approximately 0.5, Subagging achieves nearly the same prediction performance as Bagging while coming at a lower computational cost.
References
- Breiman, L.: Bagging predictors. Machine Learning, 24, 123–140 (1996).
- Bühlmann, P., Yu, B.: Analyzing bagging. Annals of Statistics 30, 927–961 (2002).




