Data-Centric AI: From Model-First to Data-First AI Processes


Given the hype and the recent success of AI it is surprising that most companies still lack the successful integration of AI. This is quite evident in many industries, especially in manufacturing. (McKinsey).
In a study published by Accenture in 2019 about the implementation of AI in companies, the authors came to the conclusion that around 80% of all Proof of Concepts (PoCs) do not make it into production. Furthermore, only 5% of all interviewed companies stated that they currently have a company-wide AI strategy in place.
These findings are thought-provoking: What exactly is going wrong and why does artificial intelligence apparently not yet make the holistic transition from successful academic studies to the real world?
1. What Is Data-Centric AI?
„Data-centric AI is the discipline of systematically engineering the data used to build an AI system.“
Andrew Ng, data-centric AI pioneer
The data-centric approach focuses on a more data-integrating AI (data-first) and less on the models (model-fist) to overcome the difficulties of AI with “reality”. Usually the training data that stands as the starting point of an AI project at companies have relatively little in common with the meticulously curated and widely used benchmark datasets such as MNIST or ImageNet.
In this article, we want to consolide different data-centric theories and frameworks in the context of an AI (project) workflow. In addition, we want to show how we approach a data-first AI implementation at statworx.
2. What´s Behind a Data-Centric Way of Thinking?
In the simplest terms, AI systems consist of two critical components: data and model (code). Data-centric thereby leans its focus more towards data, model-centric on model infrastructure – duh!
A strong model-centric leaning AI regards the data only as an extrinsic, static parameter. The iterative process of a data science project only starts after the dataset is being “delivered” with the model-related task, like train and fine tune of various model architectures. This occupies the vast portion of time in a data science project, and data pre-processing steps are only and ad-hoc duty at the beginning of each project.

In contrary, data-centric understands (automated) data processes as an integral part of any ML project. This incorporates any necessary steps to get from raw data to a final dataset. Internalizing these processes aims to enhance the quality and the methodical observability of the data.

Data-centric approaches can be consolidated into three broader categories that explain loosely the scope of the data-centric concept. In the following, we will assign buzzwords (frameworks) that are often used in the data-centric context to a specific category.
2.1. Integration of SMEs Into the Development Process as a Major Link Between Data and Model Knowledge
The integration of domain knowledge is an integral part of data-centric. It should help project teams to grow together and thus integrate the knowledge of Subject Matter Experts (SMEs) in the best way possible.
- Data Profiling:
Data scientists should not act as a one man show that only share their findings with the SMEs. With their statistical and programmatical abilities they should rather act as mediators to empower SMEs to individually dig through the data. - Human-in-the-loop Data & Model Monitoring
In similarity to profiling, this should be a central starting point to ensure that SMEs have access to the relevant components of the AI system. From this central checkpoint, not only data but also model-relevant metrics can be monitored or examples visualized and checked. Sophisticated monitoring decreases the response time drastically since errors can be directly investigated (and mitingated) – not only by data scientists.
2.2. Data Quality Management as an Agile, Automated and Iterative Process Over (Training) Data
Copiously improving the data preparation process is key to every data science project. The model itself should be an extrinsic part at first.
- Data Cataloague, Lineage & Validation:
The documentation of data should also not be an extrinsic task, which often only arises ad-hoc towards the end of a project and could become obsolete again with every change, e.g., of a model feature. Changes should be reflected dynamically and thus automate the documentation. Data catalogue frameworks provide the capabilities to store data with associated meta data (and other necessary information).
Data lineage, as a subsequent step in the data process, keeps then track of all data mingling steps that occur during the transition from raw to the final dataset. The more complex a data model, the more a lineage graph can track how a final column was created (graph below), for example, joining, filtering or other processing steps. Finally, validating the data during the input and transformation process allows for a consistent data foundation. The knowledge gained from data profiling helps here to develop validation rules and integrate them into the process.

- Data & Label Cleaning:
The necessity of data processing is ubiquitous and well-established among AI practitioners. However, label cleaning is a rather disregarded step (that, of course, only applies to classification problems). Wrongly classified datapoints can make it hard for some algorithms to reveal the right patterns in the data. - Data Drifts in Production:
Well known weak spot of (all) AI systems are drifts in data. This happens when trainings and the actual live inference data do not have the same distribution. In order to pledge the model’s prediction validity in the long run, identifying these irregularities and retraining the model accordingly is a crucial part of any ML pipeline. - Data Versioning:
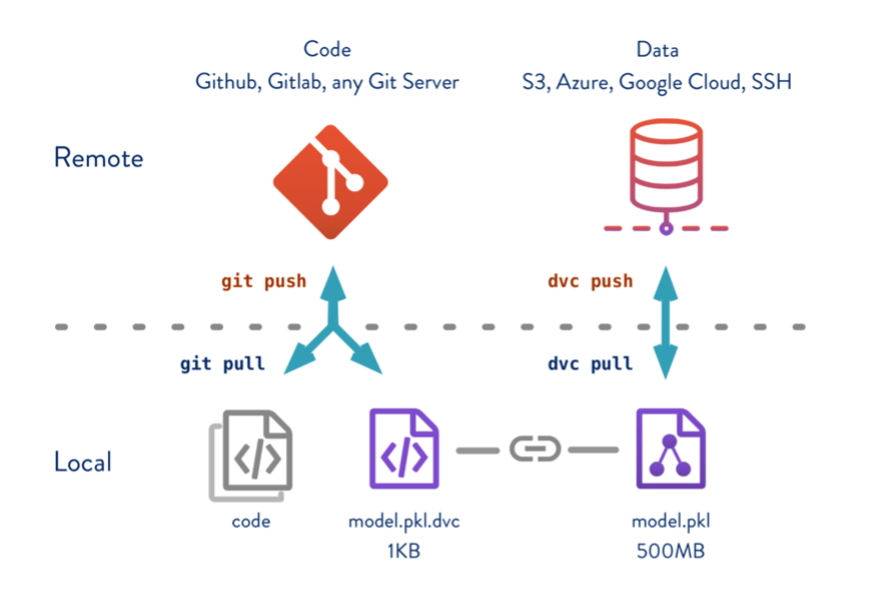
Since ever, GitHub is the go-to standard of versioning the codebase of projects. However, for AI projects it is not only important to track code but also data changes and tuck both together. This can produce a more holistic depiction of a ML workflow with increased visibility and observability.
2.3. Generating Trainings Data as Programmatic Task
Producing new (labeled) training examples is often a huge road blocker for AI projects, particularly if the underlying problem is complex and thus requires vast datasets. This may lead to an unbearable overhead of manual labor.
- Data Augmentation:
In many data-intensive deep learning models, this technique has been used for a long time to create artificial data with existing data. It, for instance, works perfectly on image data, for easy operations such as rotating, tilting or altering the color filters. Even in NLP and tabular (Excel and co.) use cases, there are possibilities to enlarge the dataset.

- Automated Data Labeling:
As already stated, labeling data is a rather labor-intense task in which people assign data points to a predefined category. On the one hand, this makes the initial effort (costs) very high, and on the other hand, it is error-prone and difficult to monitor. That’s where ML can chip in. Concepts like semi and weak supervision can automate the manual task almost entirely. - Data Selection:
Working with large chunks of data in a local setup is often not possible, especially once the dataset does not fit into memory anymore. And even if it fits, trainings runs can take forever. Data Selection tries to reduce the size by active subsampling (whether labeled or unlabeled). The “best” examples with the highest diversity and representativeness are actively selected here to ensure the best possible characterization of the input – and this is done automatically.
Needless to say, not every presented method is necessarily a good fit for every project. It is part of the work of the development team to analyze how a certain framework could benefit the final product, which also should take business considerations (e.g. cost versus benefit) into account.
3. Integration of Data-Centric at statworx
Data-centric is a crucial part of our projects, especially during the transition between PoC and production-ready model. We also had cases, in which during this transition, we faced some mainly data-related issue due to inadequate documentation, validation or poor integration of SMEs into the data process.
We therefore generally try to show our customers the importance of data management for the longevity and robustness of AI products in production and how helpful components are linked within an AI pipeline.
As part of the learnings, our data onboarding framework, a mix of profiling, catalogue and validation aims to mitigate the before mentioned issues. Additionally, this framework helps the entire company make previously unused, undocumented data sources available for various use cases (not just AI).
A strong interaction with the SMEs on the client’s side is integral to establish trustworthy, robust and well-understood quality checks. This also helps to empower our clients to debug errors and do the first-level support themselves, which also helps with the service’s longevity.

In a stripped-down, custom data onboarding integration, we used a variety of open and closed source tools to create a platform that is easily scalable and understandable for the customer. We installed validation checks with Great Expectations (GE), a python-based tool with reporting capabilities to create a shareable status report of the data.

This architecture can then run on different environments, like cloud native software (Azure DataFactory) or orchestrated with Airflow (open-source) and can be easily complemented.
4. Data-Centric in Relation AI’s Status Quo
Both data- and model-centric describe attempts on how to approach an AI project.
On the one hand, there exist already well-established best practices around model-centric with various production-proved frameworks.
One reason for this maturity is certainly the strong focus on model architectures and their advancements among academic researchers and leading AI companies. With computer vision and NLP leading the way, commercialized meta models, trained on enormous datasets, opened the door for successful AI use cases. With relatively limited data, those models can get finetuned for downstream end-use applications – known as transfer learning.
However, this trend helps only some of the failed projects, because especially in the context of industrial projects, lack of compatibility or rigidity of use cases makes the applications of meta-models difficult. Non-rigidity is often found in machine-heavy manufacturing industries, where the environment in which data is produced is constantly changing and even the replacement of a single machine can have a large impact on a productive AI model. If this issue has not been properly considered in the AI process, this creates a difficult-to-calculate risk, also known as technical debt [Quelle: https://proceedings.neurips.cc/paper/2015/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf].
Lastly, edge cases, rare and unusual datapoints are generally a burden for any AI. An application that observes anomalies of a machine component most certainly sees only a fraction of faulty units.
5. Conclusion – Paradigm Shift in Sight?
Overcoming these problems is part of the promise of data-centric, but is still rather immature at the moment.
The availability or immaturity of open-source frameworks does manifest this allegation, especially since there is a lack of a more unified tool stack end user can choose from. This inevitably leads to longer, more involved, and complex AI projects, which is a significant hurdle for many companies. In addition, there are few data metrics available to give companies feedback on what exactly they are “improving.” And second, many of the tools (eg., data catalogue) have more indirect, distributed benefits.
Some startups that aim to address these issues have emerged in recent years. However, because they (exclusively) market paid tier software, it is rather unclear to what extent these products can really cover the broad mass of problems from different use cases.
Although the above shows that companies in general are still far away from a holistic integration of data-centric, robust data strategies have become more and more important lately (as we at statworx could see in our projects).
With increased academic research into data products, this trend will certainly intensify. Not only because new, more robust frameworks will emerge, but also because university graduates will bring more knowledge in this area to companies.
Image Sources
Model-centric arch: own
Data-centric arch: own
Data lineage: https://www.researchgate.net/figure/Data-lineage-visualization-example-in-DW-environment-using-Sankey-diagram_fig7_329364764
Versioning Code/Data: https://ardigen.com/7155/
Data Augmentation: https://medium.com/secure-and-private-ai-writing-challenge/data-augmentation-increases-accuracy-of-your-model-but-how-aa1913468722
Data & AI pipeline: own
Validation with GE: https://greatexpectations.io/blog/ge-data-warehouse/




