Learning Images with Neural Networks


Convolutional Neural Networks (CNN) are a popular type of neural network architecture, which are primarily used to classify images and videos. The structure of convolutional networks is significantly different from that of the Multilayer Perceptron (MLP), which has already been used in previous posts on introduction and programming neural networks were discussed.
Convolutional and pooling layers
CNNs use a special architecture called convolutional and pooling layers. The purpose of this layer is to look at an input from different perspectives, where the spatial arrangement of the features is important. Each neuron in the convolutional layer checks a specific area of the input field using a so-called filter. A filter examines the image for a specific property, such as color composition or edges, and is in principle nothing more than a layer specially trained and responsible for this task.
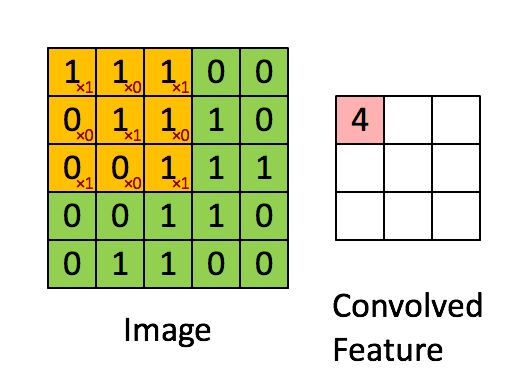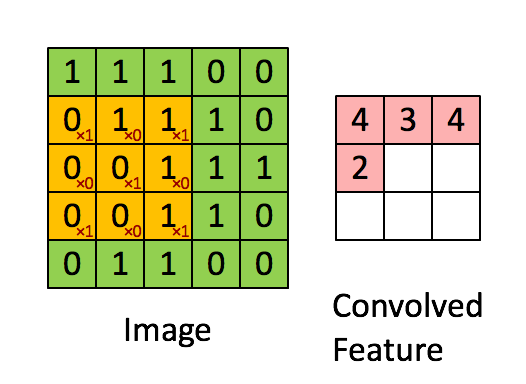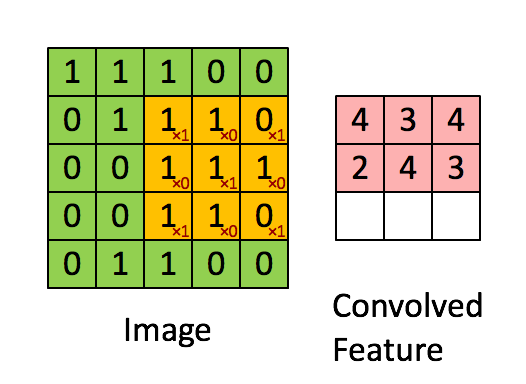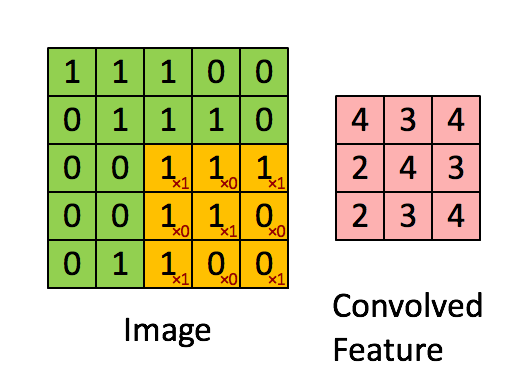
The result of a filter is the weighted input for an area and is stored in the convolutional layer. The number of convolutional layers is equal to the number of filters used, as the entire input image is checked by each filter. This information is compressed between the individual convolutional layers using so-called pooling layers. The pooling layers run the feature map created by the filters and compress it. In this case, compressing means reducing the number of pixels according to a given logic. For example, this can be a sum or the maximum value of a small area of the feature map. This is similar to convolutional layers, with the difference that the pooling layers are not trained and their logic therefore persists. This can be followed by further convolutional layers and/or pooling layers. The abstracted features are then transferred to a fully networked MLP (see figure). A higher number of layers usually results in a higher degree of abstraction of the original image. In this MLP, for example, during image classification, a final multiclass classification is carried out and the most likely class is returned. Multiclass describes a problem in which the target variable can belong to one of several classes. The counterpart to this is binary classification, in which the target variable can only assume two states.

Benchmarking and evaluation
Image classification is one of the benchmark cases for evaluating current deep learning research. Known data sets that are used for this purpose include MNIST or CIFAR10 or CIFAR100. former contains images of handwritten numbers on US Postal Service envelopes and is therefore a multi-class classification problem with 10 forms (numbers 0-9). Die CIFAR data sets contain images of animals and vehicles — in the version with 10 characteristics — or even of plants, people or even electrical devices in the data set with 100 classes. 10 and 100 represent the number of different classes represented by images in the data set. A higher number of classes is usually a more difficult problem for the algorithm. Current state-of-the-art models for image classification achieve an accuracy of up to 99.8% for MNIST, 96.5% for CIFAR-10 and 75.7% for the CIFAR-100 data set2.Of course, the deep learning frameworks Tensorflow and Keras offer a number of preconfigured components for creating convolutional neural networks. In the next blog post, we will illustrate how to create a CNN, with which we will try to learn the categories of the CIFAR-10 data set.
References
- CNN photo credit: Post on Statsexchange
- Collection of CNN benchmark results
Christian Moreau Christian Moreau




