Das häufigste Problem mit Plotly Histograms und wie man es löst


Die Datenexploration ist ein wichtiger Schritt in jedem Data Science-Projekt hier bei statworx. Um alle relevanten Erkenntnisse zu gewinnen, ziehen wir interaktive Diagramme statischen Diagrammen vor, da wir so die Möglichkeit haben, tiefer in die Daten einzudringen. Das hilft uns, alle Informationen sichtbar zu machen.
In diesem Blogbeitrag zeigen wir dir, wie du die Interaktivität von Plotly Histograms in Python verbessern kannst, wie du in der Grafik unten sehen kannst. Du findest den Code in unserem GitHub Repo.
TL;DR: Kurze Zusammenfassung
- Wir zeigen dir das Standard Histogram von Plotly und sein unerwartetes Verhalten.
- Wir verbessern das interaktive Histogram, damit es unserer menschlichen Intuition entspricht, und zeigen dir den Code.
- Wir erklären den Code Zeile für Zeile und geben dir mehr Informationen über die Implementierung.
Das Problem des Standard Histograms von Plotly
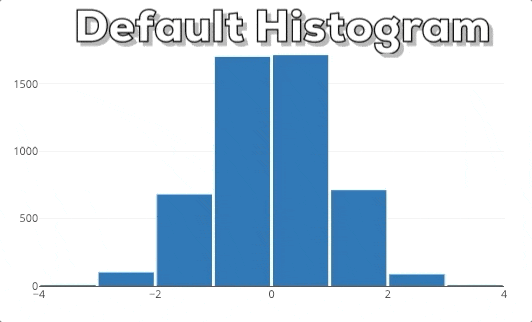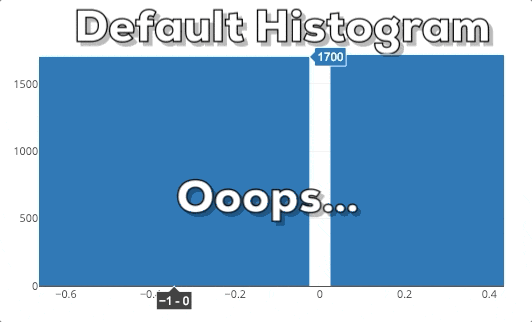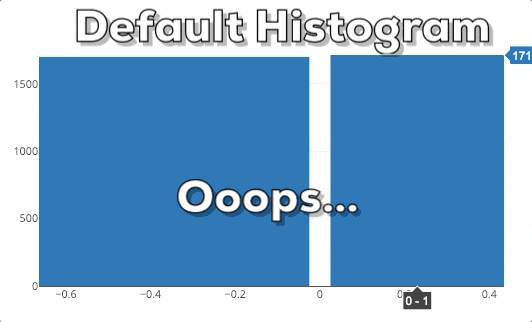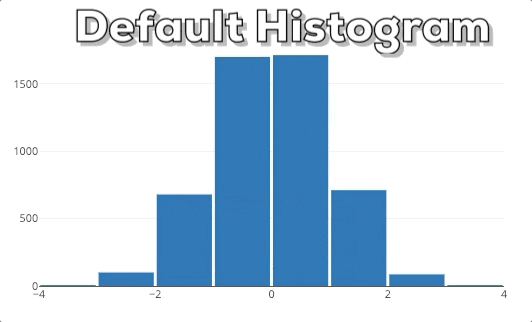
Diese Grafik zeigt dir das Verhalten eines Plotly Histograms, wenn du in eine bestimmte Region hinein zoomst. Du kannst sehen, dass die Balken einfach größer/breiter werden. Das ist nicht das, was wir erwarten! Wenn wir in ein Diagramm reinzoomen, wollen wir tiefer graben und feinere Informationen für einen bestimmten Bereich sehen. Deshalb erwarten wir, dass das Histogram detailliertere Informationen anzeigt. In diesem speziellen Fall erwarten wir, dass das Histogram Bins für die ausgewählte Region anzeigt. Daher muss das Histogram neu gebinnt werden.
Verbesserung des interaktiven Histograms
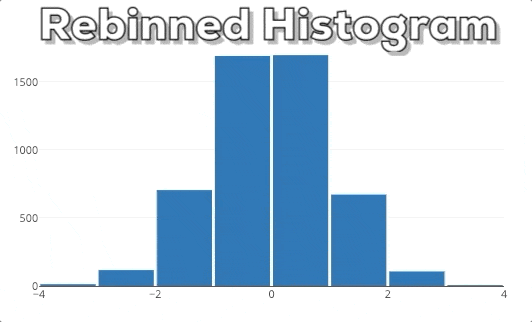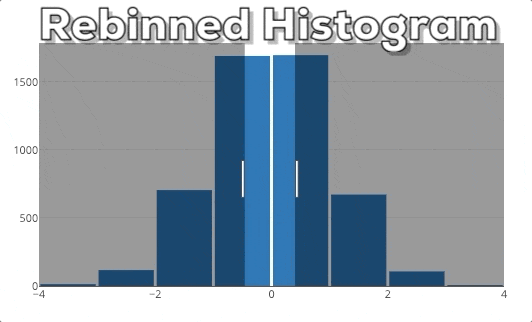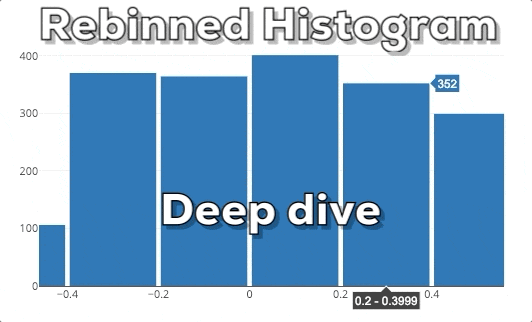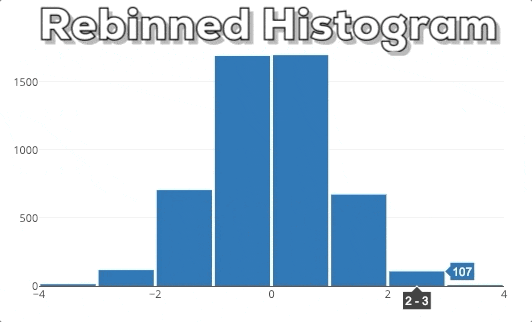
In dieser Grafik kannst du unser erwartetes Endergebnis sehen. Wenn man einen neuen x-Bereich auswählt, soll das Histogram auf der Grundlage des neuen x-Bereichs neu berechnet werden.
Um dieses Verhalten zu implementieren, müssen wir die Grafik ändern, wenn sich der ausgewählte x-Bereich ändert. Dies ist eine neue Funktion von plotly.py 3.0.0, die der großartige Jon Mease der Community zur Verfügung gestellt hat. Du kannst mehr über die neuen Funktionen von Plotly.py 3.0.0 in dieser Ankündigung lesen.
Hinweis: Die Implementierung funktioniert nur innerhalb eines Jupyter-Notebooks oder JupyterLabs, da sie einen aktiven Python-Kernel für den Callback benötigt. Sie funktioniert nicht in einem eigenständigen Python-Skript und auch nicht in einer eigenständigen HTML-Datei. Die Idee für die Umsetzung ist die folgende: Wir erstellen eine interaktive Abbildung und jedes Mal, wenn sich die X-Achse ändert, aktualisieren wir die zugrunde liegenden Daten des Histograms. Whoops, warum haben wir das Binning nicht geändert? Plotly Histograms übernehmen automatisch das Binning für die zugrunde liegenden Daten. Wir können also das Histogram die Arbeit machen lassen und nur die zugrunde liegenden Daten ändern. Das ist zwar ein wenig kontraintuitiv, spart aber eine Menge Arbeit.
Einblick in den vollständigen Code
Hier kommt also endlich der relevante Code ohne unnötige Importe usw. Wenn du den vollständigen Code sehen willst, schau bitte in diese GitHub-Datei.
x_values = np.random.randn(5000)
figure = go.FigureWidget(data=[go.Histogram(x=x_values,
nbinsx=10)],
layout=go.Layout(xaxis={'range': [-4, 4]},
bargap=0.05))
histogram = figure.data[0]
def adjust_histogram_data(xaxis, xrange):
x_values_subset = x_values[np.logical_and(xrange[0] <= x_values,
x_values <= xrange[1])]
histogram.x = x_values_subset
figure.layout.xaxis.on_change(adjust_histogram_data, 'range')Detaillierte Erklärungen für jede Codezeile
Im Folgenden geben wir einige detaillierte Einblicke und Erklärungen zu jeder Codezeile.
1) Initialisierung der x_values
x_values = np.random.randn(5000)
Wir erhalten 5000 neue zufällige x_values, die nach einer Normalverteilung ausgegeben werden. Die Werte werden von der großartigen Numpy-Bibliothek erstellt, die mit np abgekürzt wird.
2) Erstellen der figure
figure = go.FigureWidget(data=[go.Histogram(x=x_values,
nbinsx=10)],
layout=go.Layout(xaxis={'range': [-4, 4]},
bargap=0.05))
Wir erzeugen eine neue FigureWidget-Instanz. Das FigureWidget-Objekt ist das neue "magische Objekt", das von Jon Mease eingeführt wurde. Du kannst es in Jupyter Notebook oder JupyterLab wie eine normale Plotly figure anzeigen, aber es gibt einige Vorteile.Du kannst das FigureWidget auf verschiedene Arten in Python manipulieren und du kannst auch auf einige Ereignisse hören und weiteren Python-Code ausführen, was dir eine Menge Möglichkeiten gibt. Diese Flexibilität ist der große Vorteil, den sich Jon Mease ausgedacht hat. Das FigureWidget erhält die Attribute data und layout.
Als data geben wir eine Liste aller traces (sprich: Visualisierungen) an, die wir anzeigen wollen. In unserem Fall wollen wir nur ein einziges Histogram anzeigen. Die x-Werte für das Histogramm sind unsere x_values. Außerdem setzen wir die maximale Anzahl der Bins mit nbinsx auf 10. Plotly verwendet dies als Richtlinie, erzwingt aber nicht, dass der Plot genau nbinsx Bins enthält. Als layout geben wir ein neues Layout-Objekt an und setzen den Bereich der x-Achse (xaxis) auf [-4, 4]. Mit dem Argument bargap können wir das Layout dazu bringen eine Lücke zwischen den einzelnen Balken anzuzeigen. So können wir besser erkennen, wo ein Balken aufhört und der nächste beginnt. In unserem Fall wird dieser Wert auf 0.05 gesetzt.
3) Speichern einer Referenz zum Histogram
histogram = figure.data[0]
Wir erhalten den Verweis auf das Histogram, weil wir das Histogram im letzten Schritt-Updating-the-histogram-data) manipulieren wollen. Wir erhalten nicht die eigentlichen Daten, sondern einen Verweis auf das trace-Objekt von Plotly. Diese Plotly-Syntax ist vielleicht etwas irreführend, aber sie stimmt mit der Definition der Abbildung überein, in der wir auch die "traces" als "data" angegeben haben.
4) Überblick zum Callback
def adjust_histogram_data(xaxis, xrange):
x_values_subset = x_values[np.logical_and(xrange[0] <= x_values,
x_values <= xrange[1])]
hist.x = x_values_subset
figure.layout.xaxis.on_change(adjust_histogram_data, 'range')
In diesem Abschnitt legen wir zunächst fest, was wir tun wollen, wenn sich die x-Achse ändert. Danach registrieren wir die Callback-Funktion adjust_histogram_data. Wir werden das weiter aufschlüsseln, aber wir beginnen mit der letzten Zeile, weil Python diese Zeile zur Laufzeit zuerst ausführt. Deshalb ist es sinnvoller, den Code in dieser umgekehrten Reihenfolge zu lesen. Noch ein bisschen mehr Hintergrundwissen zum Callback: Der Code in der Callback-Methode adjust_histogram_data wird aufgerufen, wenn das Ereignis xaxis.on_change tatsächlich eintritt, weil Benutzende mit dem Diagramm interagiert haben. Aber zuerst muss Python die Callback-Methode adjust_histogram_dataregistrieren. Viel später, wenn das Callback-Ereignis xaxis.on_changeeintritt, wird Python die Callback-Methode adjust_histogram_data und ihren Inhalt ausführen. Lies dir diesen Abschnitt 3-4 Mal durch, bis du ihn vollständig verstanden hast.
4a) Registrierung des Callbacks
figure.layout.xaxis.on_change(adjust_histogram_data, 'range')
In dieser Zeile teilen wir dem Figure-Objekt mit, dass es die Callback-Funktion adjust_histogram_data immer dann aufrufen soll, wenn sich die X-Achse ändert. Bitte beachte, dass wir nur den Namen der Funktionadjust_histogram_dataohne die runden Klammern() angeben. Das liegt daran, dass wir nur den Verweis auf die Funktion übergeben müssen und die Funktion nicht aufrufen wollen. Das ist ein häufiger Fehler und sorgt oftmals für Verwirrung. Außerdem geben wir an, dass wir nur an dem Attribut range interessiert sind. Daher wird das figure-Objekt nur diese Information an die Callback-Funktion senden.
Aber wie sieht die Callback-Funktion aus und was ist ihre Aufgabe? Diese Fragen werden in den nächsten Schritten erklärt:
4b) Definieren der Callback-Signatur
def adjust_histogram_data(xaxis, xrange):
Hier beginnen wir, unsere Callback-Funktion zu definieren. Das erste Argument, das an die Funktion übergeben wird, ist das Objekt xaxis, das den Callback ausgelöst hat. Das ist eine Konvention von Plotly und wir müssen diesen Platzhalter nur hier einfügen, obwohl wir ihn nicht benutzen. Das zweite Argument ist der xrange, der die untere und obere Grenze der neuen xrange-Konfiguration enthält. Du fragst dich vielleicht: "Woher kommen die Argumente xaxis und xrange?" Diese Argumente werden automatisch von figure bereitgestellt, wenn der Callback aufgerufen wird. Wenn du Callbacks zum ersten Mal verwendest, mag dir das wie unergründliche Magie vorkommen. Aber du wirst dich daran gewöhnen...
4c) Aktualisieren der x_values
x_values_subset = x_values[np.logical_and(xrange[0] <= x_values,
x_values <= xrange[1])]
In dieser Zeile definieren wir unsere neuen x_values, die in den meisten Fällen eine Teilmenge der ursprünglichen x_values sind. Wenn die untere und die obere Grenze jedoch sehr weit voneinander entfernt sind, kann es passieren, dass wir alle ursprünglichen x_values auswählen. Die Teilmenge ist also nicht immer eine strenge Teilmenge. Die untere Grenze der xrange wird durch xrange[0] und die obere Grenze durch xrange[1] definiert. Um die Teilmenge der x_values auszuwählen, die innerhalb der unteren und oberen Grenze des Bereichs liegt, verwenden wir die Funktion logical_and von Numpy. Es gibt mehrere Möglichkeiten, wie wir in Python Teilmengen von Daten auswählen können. Zum Beispiel kannst du das auch über Pandas-Selektoren tun, wenn du Pandas Dataframes/Series verwendest.
4d) Aktualisieren der Histogram-Daten
histogram.x = x_values_subset
In dieser Zeile aktualisieren wir die zugrundeliegenden Daten des Histograms und setzen sie auf das neue x_values_subset. Diese Zeile löst die Aktualisierung des Histograms und das automatische Rebinning aus. Das histogram ist der Verweis, den wir in Schritt 3 des Codes erstellt haben, weil wir ihn hier brauchen.
Fazit
In diesem Blogbeitrag haben wir dir gezeigt, wie du das Standard-Histogram von Plotly durch interaktives Binning verbessern kannst. Wir haben dir den Code gegeben und jede Zeile der Implementierung erklärt. Wir hoffen, dass du uns folgen konntest und ein gutes Verständnis für die neuen Möglichkeiten von plotly.py 3.0.0 gewonnen hast.
Vielleicht hast du manchmal das Gefühl, dass du den Code, den du im Internet oder auf Stackoverflow findest, nicht gut verstehst. Wenn du intuitive Erklärungen für Themen aus Data Science-Welt suchst, solltest du dir einige unserer offenen Kurse ansehen, die von unseren Data Science-Expert:innen hier bei statworx unterrichtet werden.
Quellen
- Offizielles plotly.py GitHub-Repository https://github.com/plotly/plotly.py
- Offizielle Übersicht über alle neuen Funktionen von plotly.py 3.0.0 https://medium.com/@plotlygraphs/introducing-plotly-py-3-0-0-7bb1333f69c6


