Wie man mit Call Graph automatisch Projektgrafiken erstellt


Einführung
Je komplexer ein beliebiges Data Science Projekt in Python wird, desto schwieriger wird es in der Regel, den Überblick darüber zu behalten, wie alle Module miteinander interagieren. Wenn man in einem Team an einem größeren Projekt arbeitet, wie es hier bei STATWORX oft der Fall ist, kann die Codebasis schnell so groß werden, dass die Komplexität abschreckend wirken kann. In einem typischen Szenario arbeitet jedes Teammitglied in seiner “Ecke” des Projekts, so dass jeder nur über ein solides lokales Wissen über den Code des Projekts verfügt, aber möglicherweise nur eine vage Vorstellung von der Gesamtarchitektur des Projekts hat. Im Idealfall sollte jedoch jeder, der an dem Projekt beteiligt ist, einen guten globalen Überblick über das Projekt haben. Damit meine ich nicht, dass man wissen muss, wie jede Funktion intern funktioniert, sondern eher, dass man die Zuständigkeit der Hauptmodule kennt und weiß, wie sie miteinander verbunden sind.
Ein visuelles Hilfsmittel, um die globale Struktur kennenzulernen, kann ein Call Graph sein. Ein Call Graph ist ein gerichteter Graph, der anzeigt, welche Funktion welche Funktion aufruft. Er wird aus den Daten eines Python-Profilers wie cProfile erstellt.
Da sich ein solcher Graph in einem Projekt, an dem ich arbeite, als hilfreich erwiesen hat, habe ich ein Paket namens project_graph erstellt, das einen solchen Call Graph für ein beliebiges Python-Skript erstellt. Das Paket erstellt ein Profil des gegebenen Skripts über cProfile, konvertiert es in einen gefilterten Punktgraphen über gprof2dot und exportiert es schließlich als .png-Datei.
Warum sind Projektgrafiken nützlich?
Als erstes kleines Beispiel soll dieses einfache Modul dienen.
# test_script.py
import time
from tests.goodnight import sleep_five_seconds
def sleep_one_seconds():
time.sleep(1)
def sleep_two_seconds():
time.sleep(2)
for i in range(3):
sleep_one_seconds()
sleep_two_seconds()
sleep_five_seconds()
Nach der Installation (siehe unten) wird durch Eingabe von project_graph test_script.py in die Kommandozeile die folgende png-Datei neben dem Skript platziert:

Das zu profilierende Skript dient immer als Ausgangspunkt und ist die Wurzel des Baums. Jedes Kästchen ist mit dem Namen einer Funktion, dem Gesamtprozentsatz der in der Funktion verbrachten Zeit und der Anzahl ihrer Aufrufe beschriftet. Die Zahl in Klammern gibt an, wieviel Zeit innerhalb einer Funktion verbracht wurde, jedoch ohne die Zeit in weiteren Unterfunktion zu berücksichtigen.
In diesem Fall wird die gesamte Zeit in der Funktion sleep des externen Moduls time verbracht, weshalb die Zahl 0,00% beträgt. In selbstgeschriebenen Funktionen wird nur selten viel Zeit verbracht, da die Arbeitslast eines Skripts in der Regel schnell auf sehr einfache Funktionen der Python-Implementierung selbst rausläuft. Neben den Pfeilen ist auch die Zeit angegeben, die eine Funktion an die andere weitergibt, zusammen mit der Anzahl der Aufrufe. Die Farben (ROT-GRÜN-BLAU, absteigend) und die Dicke der Pfeile zeigen die Relevanz der verschiedenen Stellen im Programm an.
Beachten Sie, dass sich die Prozentsätze der drei obigen Funktionen nicht zu 100 % aufaddieren. Der Grund dafür ist, dass der Graph so eingestellt ist, dass er nur selbst geschriebene Funktionen enthält. In diesem Fall hat das Importieren des Moduls time den Python-Interpreter dazu veranlasst, 0,04% der Zeit für eine Funktion des Moduls importlib aufzuwenden.
Auswertung mit externen Packages
Betrachten wir ein zweites Beispiel:
# test_script_2.py
import pandas as pd
from tests.goodnight import sleep_five_seconds
# some random madness
for i in range(1000):
a_frame = pd.DataFrame([[1,2,3]])
sleep_five_seconds()
In diesem Skript wird ein Teil der Arbeit in einem externen Paket erledigt, das auf der Top-Ebene und nicht in einer benutzerdefinierten Funktion aufgerufen wird. Um dies im Graphen zu erfassen, können wir das externe Paket (pandas) mit der Flag -x hinzufügen. Die Initialisierung eines Pandas DataFrame wird jedoch in vielen Pandas-internen Funktionen durchgeführt. Offen gesagt, bin ich persönlich nicht an den inneren Verwicklungen von pandas interessiert, weshalb ich möchte, dass der Baum nicht zu tief in die Pandas-Mechanik “hineinwächst”. Diesem Umstand kann man Rechnung tragen, indem man nur Funktionen auftauchen lässt, die einen minimalen Prozentsatz der Laufzeit in ihnen verbringen. Genau dies kann mit der -m-Flag erreicht werden.
In Kombination ergibt project_graph -m 8 -x pandas test_script_2.py das folgende Ergebnis:

Spaß(-Beispiele) beiseite, nun wollen wir uns ernsteren Dingen zuwenden. Ein echtes Data Science Projekt könnte wie dieses aussehen:
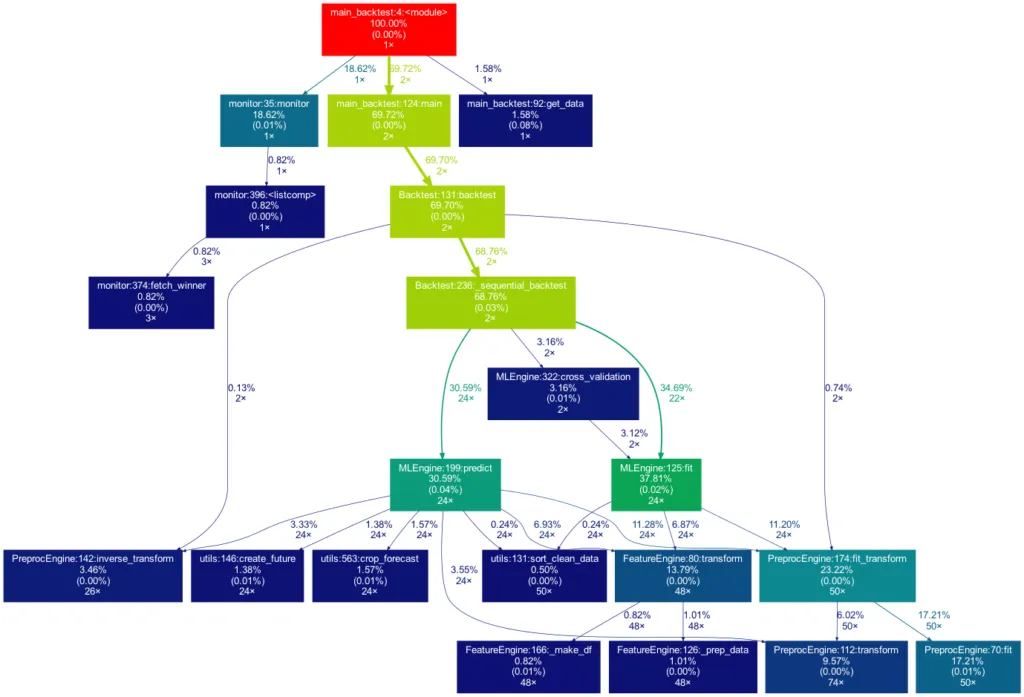
Dieses Mal ist der Baum viel größer. Er ist sogar noch größer als in der Abbildung zu sehen, da viel mehr selbst geschriebene Funktionen aufgerufen werden. Sie werden jedoch aus Gründen der Übersichtlichkeit aus dem Baum entfernt, da Funktionen, für die weniger als 0,5 % der Gesamtzeit aufgewendet werden, herausgefiltert werden (dies ist die Standardeinstellung für die -m Flag). Beachten Sie, dass ein solches Diagramm auch bei der Suche nach Leistungsengpässen sehr vorteilhaft ist. Man sieht sofort, welche Funktionen den größten Teil der Arbeitslast tragen, wann sie aufgerufen werden und wie oft sie aufgerufen werden. Das kann Sie davor bewahren, Ihr Programm an den falschen Stellen zu optimieren und dabei den Elefanten im Raum zu übersehen.
Wie man project graph verwendet
Installation
Gehen Sie in Ihrer Projektumgebung wie folgt vor:
brew install graphviz
pip install git+https://github.com/fior-di-latte/project_graph.gitVerwendung
Wechseln Sie in der Projektumgebung in das aktuelle Arbeitsverzeichnis des Projekts (das ist wichtig!) und geben Sie für die Standardverwendung ein:
project_graph myscript.py
Wenn Ihr Skript einen argparser enthält, verwenden Sie (vergessen Sie nicht die Anführungsstriche!):
project_graph "myscript.py <arg1> <arg2> (...)"
Wenn Sie den gesamten Graphen sehen wollen, einschließlich aller externen Pakete, verwenden Sie:
project_graph -a myscript.py
Wenn Sie eine andere Sichtbarkeitsschwelle als 1% verwenden wollen, benutzen Sie:
project_graph -m <percent_value> myscript.py
Wenn Sie schließlich externe Pakete in den Graphen aufnehmen wollen, können Sie sie wie folgt angeben:
project_graph -x <package1> -x <package2> (...) myscript.py
Schluss & Hinweise
Dieses Paket hat einige Schwächen, von denen die meisten behoben werden können, z.B. durch Formatierung des Codes in einen funktionsbasierten Stil, durch Trimmen mit der -m-Flag oder durch Hinzufügen von Paketen mit der-x-Flag. Wenn etwas seltsam erscheint ist der erste Schritt wahrscheinlich die Verwendung der -a-Flag zur Fehlersuche. Wesentliche Einschränkungen sind die folgenden:
- Es funktioniert nur auf Unix-Systemen.
- Es zeigt keinen wahrheitsgetreuen Graphen an, wenn es mit Multiprocessing verwendet wird. Der Grund dafür ist, dass cProfile nicht mit Multiprocessing kompatibel ist. Wenn Multiprocessing verwendet wird, wird nur der Root-Prozess profiliert, was zu falschen Berechnungszeiten im Graphen führt. Wechseln Sie zu einer nicht-parallelen Version des Zielskripts.
- Die Profilerstellung eines Skripts kann zu einem beträchtlichen Overhead bei der Berechnung führen. Es kann sinnvoll sein, die in Ihrem Skript geleistete Arbeit zu verringern (d. h. die Menge der Eingabedaten zu reduzieren). In diesem Fall kann die in den Funktionen verbrachte Zeit natürlich massiv verzerrt werden, wenn die Funktionen nicht linear skalieren.
- Verschachtelte Funktionen werden im Diagramm nicht angezeigt. Insbesondere ein Dekorator verschachtelt implizit Ihre Funktion und versteckt sie daher. Das heißt, wenn Sie einen externen Dekorator verwenden, vergessen Sie nicht, das Paket des Dekorators über die
-xFlag hinzuzufügen (zum Beispielproject_graph -x numba myscript.py). - Wenn Ihre selbst geschriebene Funktion ausschließlich von einer Funktion eines externen Pakets aufgerufen wird, müssen Sie das externe Paket manuell mit der
-xFlag hinzufügen. Andernfalls wird Ihre Funktion nicht im Baum auftauchen, da ihr Parent eine externe Funktion ist und daher nicht berücksichtigt wird.
Sie können das kleine Paket gerne für Ihr eigenes Projekt verwenden, sei es für Leistungsanalysen, Code-Einführungen für neue Teammitglieder oder aus reiner Neugier. Was mich betrifft, so finde ich es sehr befriedigend, eine solche Visualisierung meiner Projekte zu sehen. Wenn Sie Probleme bei der Verwendung haben, zögern Sie nicht, mich auf Github zu kontaktieren (https://github.com/fior-di-latte/project_graph/).
PS: Wenn Sie nach einem ähnlichen Paket in R suchen, sehen Sie sich Jakobs Beitrag über Flussdiagramme von Funktionen an.


