Eine Einführung in Dataiku DSS


In den meisten unserer Kundenprojekte bei statworx nutzen wir R oder Python. Auch in unserem Blog handelt es sich meist um Themen rund um die Nutzung dieser beiden Sprachen. Im Data Science Bereich gibt es allerdings eine große Anzahl anderer Tools, viele davon mit einer grafischen Benutzeroberfläche. Dazu zählen zum Beispiel KNIME, RapidMiner oder das hier vorgestellte Tool von Dataiku Data Science Studio (DSS). Allen gemeinsam ist, dass keine besonderen Programmierkenntnisse benötigt werden, um mit diesen zu arbeiten. Die Tools bieten also auch Data Science Einsteigern eine gute Möglichkeit schnelle Ergebnisse zu erzielen und diese mit Kollegen aus anderen Fachbereichen einfach zu teilen. Dies ist einer der Gründe warum auch wir in einigen Kundenprojekten mit Dataiku DSS arbeiten und zu diesem Tool auch Schulungen anbieten.
In dem ersten Teil des Artikels soll ein erster Überblick über die Funktionen von Dataiku DSS gegeben werden, im Folgenden werde ich die Möglichkeiten an einem Beispieldatensatz aufzeigen.
Das wichtigste allerdings zuerst. Wenn Sie sich selbst ein Bild von Dataiku machen wollen und das untere Beispiel nachvollziehen möchten, können Sie eine kostenlose Version auf Dataiku herunterladen.
Vorstellung Dataiku
Warum Dataiku Ihren Arbeitsablauf erleichtern wird?
Das im Jahr 2013 gegründete Unternehmen Dataiku bietet eine kollaborative Data Science Plattform, die die Bearbeitung des gesamten Workflows eines Data Sciences Projektes erlaubt. Dies umfasst die Integration von Hadoop oder Spark, die Datentransformation mit einer grafischen Benutzeroberfläche, dem Nutzen von diversen Algorithmen des maschinellen Lernens und die Datenvisualisierung mit Dashboards. Durch die Breite an Funktionen kann das Tool von Data Scientists, Data Analysts und Data Engineers genutzt werden. Weiterhin ist das Projektmanagement über Dataiku zum Beispiel durch To-do-Listen möglich.
Durch die diversen Funktionen wurde Dataiku im Jahr 2018 im Gartner Magic Quadrant for Data Science Platforms als Visionär eingeordnet.
Ein großer Vorteil an Dataiku ist die Click-or-Code Option. Diese Option ermöglicht es entweder die grafische Oberfläche oder R/Python Code zu nutzen, um zum Beispiel die Datenaufbereitung durchzuführen. Dadurch können beliebige Funktion selbst erstellt werden, sollte der vordefinierte Funktionsumfang nicht ausreichen. Die grafische Benutzeroberfläche bietet dabei eine große Menge an Funktionen und eine ähnliche Syntax wie Excel.
Der Aufbau von Dataiku DSS
Auf der Startseite befindet sich eine Übersicht über alle Projekte. Hier wurde neben zwei Beispielen von Dataiku DSS noch ein weiteres Testprojekt erstellt. Bei einer größeren Anzahl Projekte, ist es zudem möglich nach diesen zu suchen.
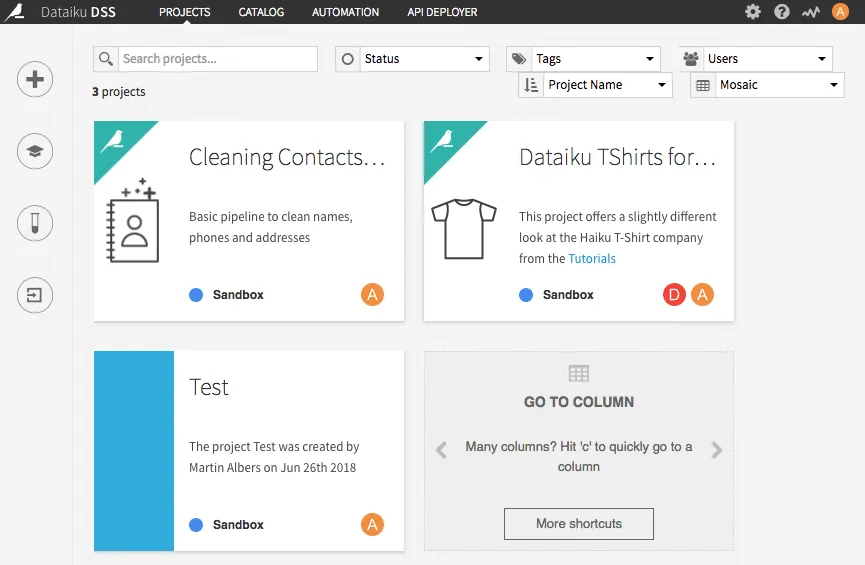
Klickt man auf eines der Projekte, öffnet sich eine Zusammenfassung des Projektes mit der Anzahl genutzter Datensätze, Modelle, Dashboards usw..
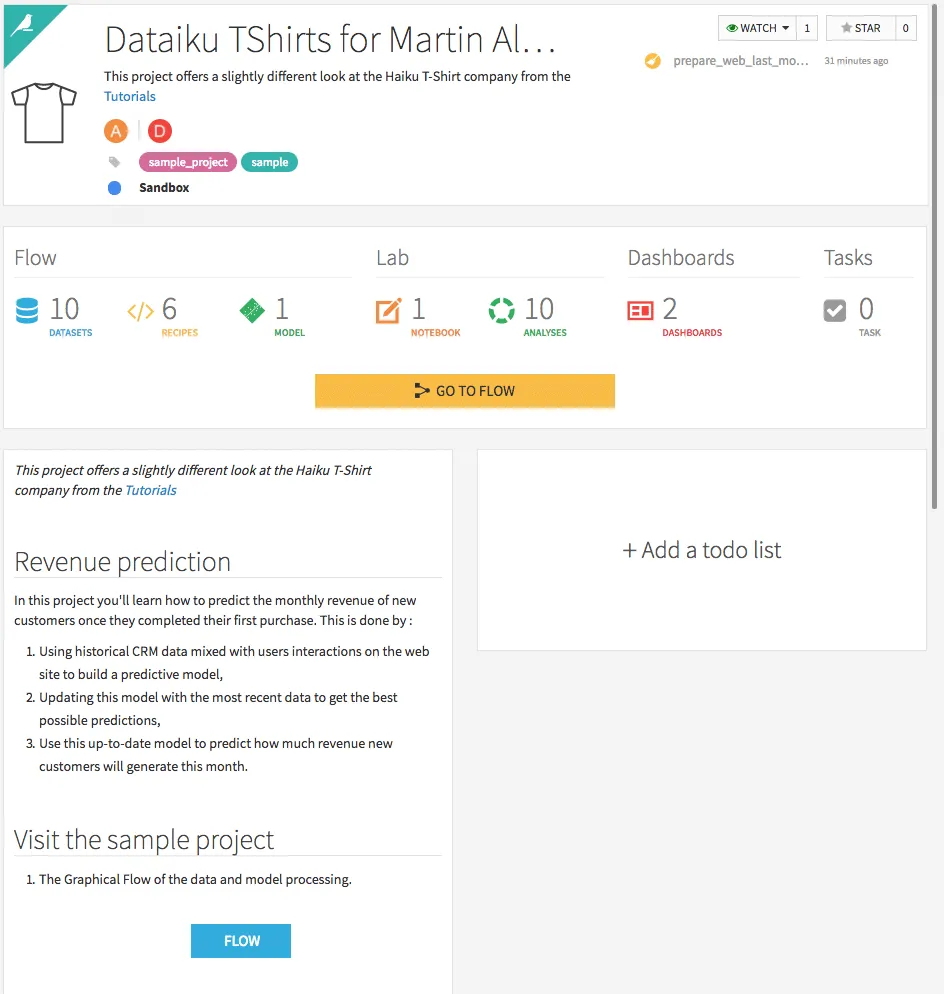
Zusätzlich kann eine kurze Zusammenfassung des Projektes, ähnlich einer Readme-Datei auf Github, sowie eine To-do-Liste erstellt werden. Weiterhin können über den Reiter "Changes" Veränderungen nachverfolgt werden.
Klickt man auf den Button GO TO FLOW öffnet man den Workflow des Projektes.
Der angezeigte Workflow wird von links nach rechts durchlaufen und zeigt die Implementierung eines einfachen Modells. Zuerst werden dabei verschieden Datensätze geladen. In den nächsten Schritten erfolgt dann ein Join, die Datenaufbereitung, das Training sowie als letzter Schritt das Scoring der Modelle.
Ein Vorteil an dem Workflow ist neben der guten Übersicht, dass man die einzelnen Schritte schnell bearbeiten kann und Änderungen an den Datensätzen direkt beobachten kann. Durch einen Doppelklick auf den erstellten Datensatz web_last_month_enriched ist es zum Beispiel möglich zu sehen, was sich verändert hat und in welchem Format die einzelnen Spalten gespeichert sind. Gerade bei unbekannten Datensätzen hilft dies einen schnellen Überblick über die Daten zu bekommen.
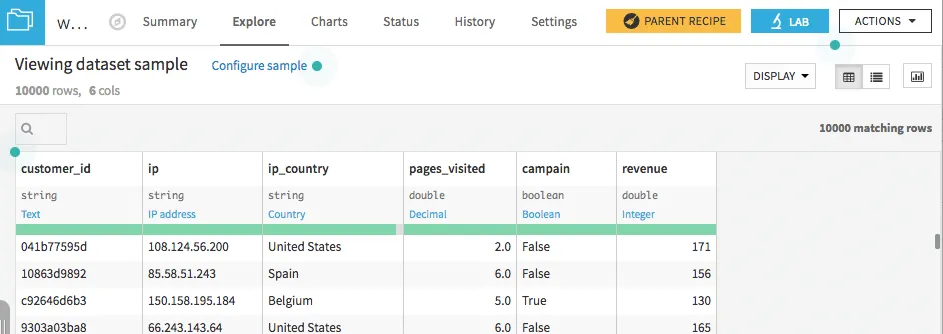
Vorhersage der Weinqualität - ein Beispiel
Als Beispiel soll ein Problem gewählt werden, bei dem anhand von verschiedenen Einflussvariablen die Qualität eines Weines vorhergesagt werden muss. Die beiden genutzten Datensätze können auf der Seite vom UCI Machine Learning Repository unter UCI Datasets heruntergeladen werden. Ein Datensatz enthält dabei jeweils Daten einer Weinsorte.
Die Qualität eines Weines wird dabei anhand einer Skala von 0-10 bewertet, wobei die 10 der höchsten Kategorie entspricht. Als Einflussvariablen werden verschiedene sensorische Daten wie zum Beispiel der pH-Wert oder der Gesamtschwefeldioxidgehalt genutzt. Die Bedeutung der einzelnen Variablen kann genauer in Dataset Description nachgelesen werden. Für diesen Blog wird dabei die Qualität des Weines in nur zwei Gruppen eingeteilt. Dazu werden alle "schlechten" Weine mit einer Wertung kleiner gleich 5 in einer Kategorie zusammengefasst und alle Weine mit einer Wertung größer als 5 in einer anderen Kategorie zusammengefasst.
Als erster Schritt müssen die Datensätze hochgeladen und zusammengeführt werden. Um einen neuen Datensatz in Dataiku zu nutzen kann das Datenbank Symbol genutzt werden. Danach werden die verschiedenen Möglichkeiten von Datenquellen angezeigt. Entweder werden verschiedene Datenbankanbindungen genutzt oder es können csv-Dateien geladen werden. Für das jetzige Problem müssen die beiden Datensätze für Rot- und Weißwein als csv-Dateien geladen werden. Direkt nach dem Laden des Datensatzes, wird dieser mit den entsprechenden Variablentypen angezeigt. In den meisten Fällen stimmen die vorgeschlagenen Werte, sollten diese doch abweichen, können die Werte auch direkt geändert werden.
Weiterhin kann durch einen Klick auf den Variablennamen und Analyze direkt eine Übersicht über die Variable gewonnen werden. Unter dem Reiter Charts gibt es zusätzlich die Möglichkeit durch Drag & Drop einfache Grafiken zu erstellen, um somit einen Überblick über die Daten zu erlangen, wobei zwischen verschiedenen Diagrammarten ausgewählt werden kann. Gerade bei unbekannten Datensätzen ist dies ein wichtiger Schritt, um die Daten zu verstehen und eventuell neue Features zu bilden oder Ausreißer zu erkennen.
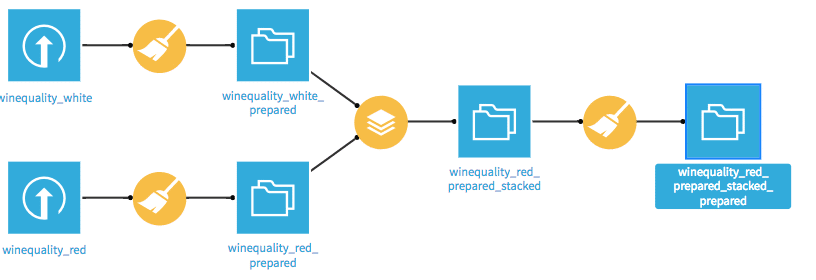
Nachdem beide Datensätze geladen wurden, müssen diese zusammengeführt werden. Dazu muss zunächst über den kleinen abgebildeten Graphen oben links die Flow-Ansicht aufgerufen werden. In dieser Ansicht werden alle Schritte der Modellierung von der Datenaufbereitung bis zum letztendlichen Deployment grapfisch durch ein Flussdiagramm angezeigt. Dabei werden verschiedene Symbole für Datensätze und diverse Operationen genutzt. Für das Zusammenführen der Daten wird in der Flow-Ansicht das Stacking-Symbol genutzt.
In der darauffolgenden Ansicht muss der jeweils andere Datensatz ausgewählt werden sowie der Name des neuen Datensatzes gewählt werden.
Für unser Problem soll nur ein Modell gebildet werden und die Farbe des Weins als Einflussvariable mit aufgenommen werden. Dazu muss zunächst bei beiden Datensätzen eine neue Variable gebildet werden, in der die jeweilige Farbe, also weiß oder rot steht. Klickt man nun in der Flow Ansicht einmal auf den Datensatz, werden verschiedene Visual Recipes angezeigt, die für verschiedene Operationen stehen. Das Hinzufügen der Weinfarbe ist ein Datenvorbereitungsschritt, weshalb auf das Symbol mit dem Besen geklickt werden muss. Danach können einer oder mehrere Datenvorbereitungsschritte durchgeführt werden. Dazu kann über Add a new step ein neuer Schritt hinzugefügt werden. Um die neue Variable hinzuzufügen kann über ein Klick bei Strings und die Auswahl Formula eine Formel eingegeben werden. Die neue Variable wird wine_color genannt und als Expression wird die entsprechende Farbe, also entweder white oder red eingetragen.
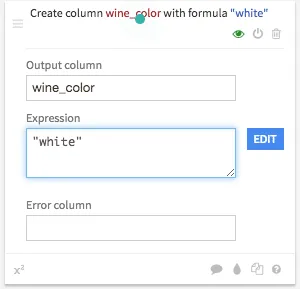
Durch eins Klick auf RUN wird die entsprechende Operation durchgeführt.
Nachdem die Datensätze zusammengeführt wurden, werden die neuen Kategorien gebildet. Dazu wird wieder das Datenaufbereitungssymbol genutzt. Darauf wird wieder über String>Formula der Formeleditor geöffnet. Die zugehörige Formel lautet if (quality <= 5, '0', '1'). Die neue Variable wird quality_classification genannt. Um beim Training die Variable quality nicht als Einflussvariable zu nutzen, wird diese im nächsten Schritt ausgeschlossen. Dazu wird unter der Kategorie Filter und Delete/Keep columns by name die Variable quality eingesetzt. Durch einen Klick auf RUN werden die entsprechenden Schritte durchgeführt.
Im Folgenden erfolgt das eigentliche Training des Modells. Um ein Modell zu trainieren reicht ein einfacher Klick auf den Trainingsdatensatz und danach kann über Lab > Visual Analysis > New ein neues Modell trainiert werden. In der neuen Ansicht kann nun unter dem Reiter Models das erste Modell erstellt werden. Nach der Auswahl des Machine Learning Problems, in unserem Fall Prediction, und der Zielvariable, kann direkt ein einfaches Modell trainiert werden oder über den Reiter Design können eigene Modelle erstellt werden.
In dem Design können verschiedene Parameter verändert werden sowie die einzelnen Algorithmen ausgewählt werden. Es gibt dabei die vier Kategorien BASIC, FEATURES, MODELING und ADVANCED.
In der Kategorie BASIC können Parameter für den Train/Test Split sowie das zu optimierende Fehlermaß angegeben werden. Sollen weitere Feature Engineering Schritte durchgeführt oder einzelne Variablen ausgeschlossen werden, kann dies in der Kategorie FEATURES geschehen. Hierbei können auch verschiedene Interaktionen zwischen den verschiedenen Variablen sowie der Umgang mit fehlenden Werten definiert werden. Unter der Kategorie MODELING gibt es eine Auswahl nahezu aller gängigen Machine-Learning Modelle wie zum Beispiel verschiedene baumbasierte Verfahren, Regressionsverfahren und Neuronale Netze. Zu jedem Modell können verschiedene Hyperparameter angegeben werden, die zum Grid-Search genutzt werden sollen. Sollen weitere Modelle ausprobiert werden, können unter dem Punkt Add Custom Python Model auch eigene Modelle entwickelt werden. Über ADVANCED kann die Python Umgebung verändert werden sowie die Gewichte der einzelnen Obersevationen verändert werden.
In dem Beispiel wurden die beiden von Dataiku vorgeschlagenen Modelle Random Forest und Logistische Regression sowie der XGBoost getestet. Durch einen Klick auf Train werden die Modelle trainiert. Am Ende des Trainings werden zu jedem Modell die durch Grid Seach ermittelten optimalen Parameter, eine Liste der wichtigsten Parameter, die Aufteilung von Trainings- und Testset sowie die Trainingszeit angezeigt. Durch einen Klick auf ein Modell werden diverse Informationen zu dem Modell angezeigt, wie zum Beispiel Werte zur Performance oder zu genutzen Input Variablen.
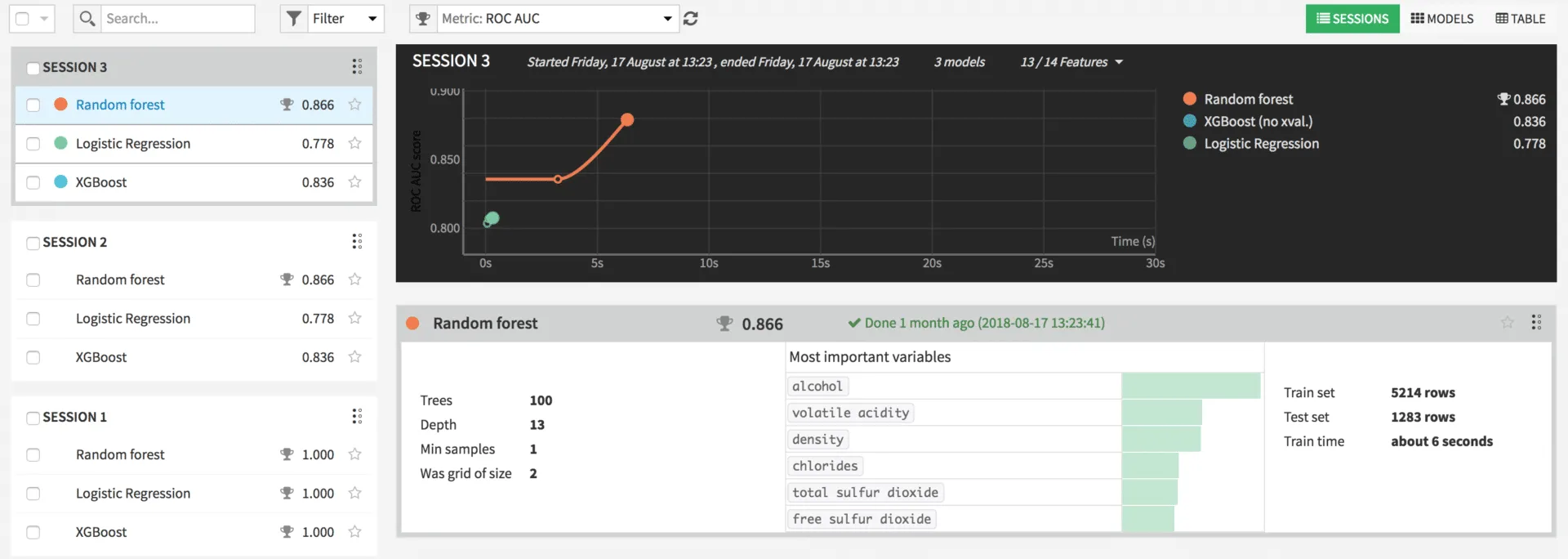
In realen Problemen kann es natürlich noch andere Kriterien als die Accuracy für die Auswahl des Modells geben, wie zum Beispiel die Interpretierbarkeit eines Modells oder lineare Zusammenhänge. Zur Produktivsetzung kann in der Detailansicht des Modells der Deploy Button betätigt werden. Das Modell kann nun auf neue Daten angewandt werden.
Der gesamte Flow hat nun folgende Form:
Resümee und Ausblick
Dieser Beitrag sollte einen ersten Überblick über das Tool geben. Natürlich gibt es noch viele weitere Funktionen auf die vorerst nicht eingegangen wurde.
Ich hoffe jedoch, dass ich Ihr Interesse geweckt habe. Bei der Bearbeitung unserer Projekte erleichtert Dataiku DSS uns die Arbeit häufig stark, zusätzlich erkennen wir bei unseren Schulungen, dass das Tool leicht zu erlernen ist. Gerade für Personen, die vorher wenig mit Daten gearbeitet haben.


