Testen von REST-APIs mit Newman


REST-APIs sind zu einem Quasi-Standard geworden, sei es, um eine Schnittstelle zu deinen Anwendungsprozessen bereitzustellen, oder um eine flexible Microservice-Architektur aufzubauen. Früher oder später stellt sich die Frage, wie ein geeignetes Testschema aussehen könnte und welche Tools einen dabei unterstützen können. Vor einiger Zeit haben wir uns diese Frage bei statworx selbst gestellt. Ein Toolset, das uns dabei hilft, ist Newman und Postman, welches ich dir in diesem Blogpost vorstellen möchte.
Viele von euch, die regelmäßig mit REST arbeiten und entwickeln, sind wahrscheinlich bereits mit Postman vertraut. Es handelt sich um ein praktisches und komfortables Desktop-Tool, das einige hervorragende Funktionen mitbringt (siehe unten). Newman hingegen ist ein Kommandozeilen-Agent, der die zuvor definierten Requests ausführt. Aufgrund seiner schlanken Schnittstelle kann es in vielen Situationen eingesetzt werden, zum Beispiel lässt es sich leicht in die Testphasen von Pipelines integrieren.

Im Folgenden werde ich erklären, wie diese Geschwistertools genutzt werden können, um eine saubere Testumgebung aufzubauen. Wir beginnen mit den Funktionsumfängen von Postman, gehen dann auf die Interaktion mit Newman ein, betrachten ein Testschema mit einigen Testfällen und integrieren das Ganze schließlich in eine Jenkins-Pipeline.
Über Postman
Postman ist ein praktisches Desktop-Tool zur Handhabung von REST-Requests. Darüber hinaus bietet dir Postman die Möglichkeit, Testfälle (in JavaScript) zu definieren, Umgebungen zu wechseln und sogenannte Pre-Request-Schritte durchzuführen, um die Umgebung vor den eigentlichen Calls aufzusetzen. Im Folgenden gebe ich dir Beispiele für einige interessante Funktionen.
Collection und Requests
Requests sind die Basiseinheit in Postman, und alles andere dreht sich um sie. Wie bereits erwähnt, stellt dir Postmans GUI eine komfortable Möglichkeit zur Verfügung, diese zu definieren: Die Request-Methode kann aus einer Dropdown-Liste ausgewählt werden, Header-Informationen sind übersichtlich dargestellt, es gibt eine Hilfe für Autorisierungen und vieles mehr.

Du solltest mindestens eine Collection pro REST-Schnittstelle definiert haben, um deine Requests zu bündeln. Am Ende des Definitionsprozesses können Collections im JSON-Format exportiert werden. Dieses Ergebnis wird später für Newman genutzt.
Environments
Postman implementiert außerdem das Konzept von Umgebungsvariablen. Das bedeutet: Abhängig davon, von wo deine Requests gesendet werden, passen sich die Variablen an. Ein gutes Beispiel hierfür ist der Hostname der API: In der Entwicklungsumgebung ist das vielleicht nur dein localhost, in einer dockerisierten Umgebung kann er jedoch anders aussehen.

Die Syntax für Umgebungsvariablen besteht aus doppelten geschweiften Klammern. Wenn du also die Hostname-Variable hostname verwenden möchtest, sieht das so aus: {{ hostname }}

Wie bei Collections können auch Environments in JSON-Dateien exportiert werden. Das sollten wir im Hinterkopf behalten, wenn wir später zu Newman wechseln.
Tests
Jeder API-Request in Postman sollte mindestens einen Test enthalten. Ich schlage folgende Liste als Orientierung vor, was getestet werden sollte:
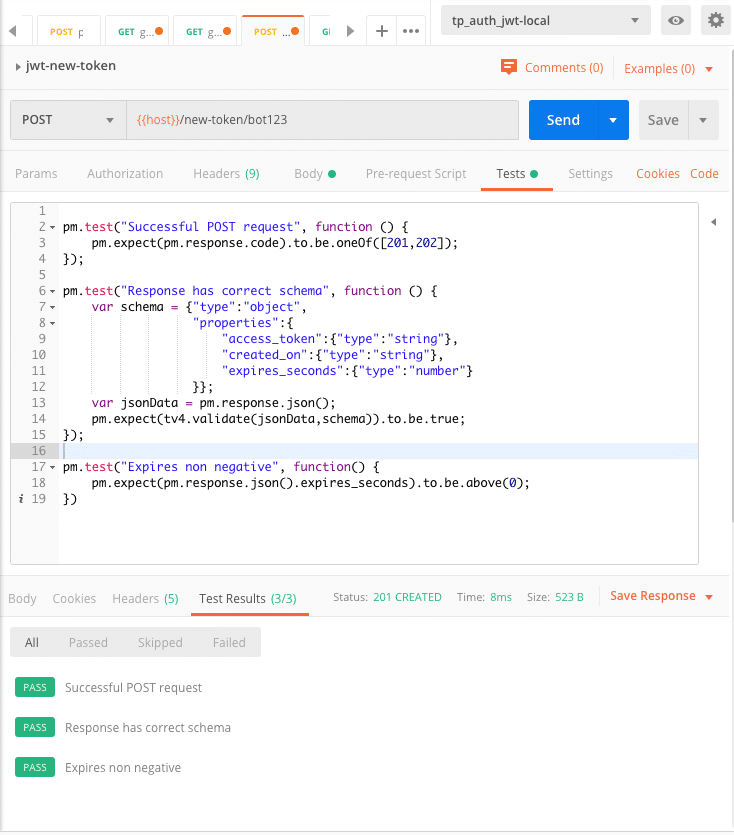
- den Statuscode: Überprüfe den Statuscode entsprechend deiner Erwartung: reguläre GET-Requests sollten 200 OK zurückgeben, erfolgreiche POST-Requests 201 Created. Andererseits sollten auch Autorisierung und ungültige Client-Requests getestet werden, die üblicherweise mit einem 40x-Fehler antworten. – Siehe unten ein POST-Request-Test:
pm.test("Successful POST request", function () {
pm.expect(pm.response.code).to.be.oneOf([201,202]);
});- ob Daten zurückgegeben werden: Teste, ob die Antwort überhaupt Daten enthält, als erste Annäherung
- das Schema der zurückgegebenen Daten: Teste, ob die Struktur der Antwortdaten den Erwartungen entspricht: nicht-nullbare Felder, Datentypen, Namen der Eigenschaften. Unten findest du ein Beispiel für eine Schema-Validierung:
pm.test("Response has correct schema", function () {
var schema = {"type":"object",
"properties":{
"access_token":{"type":"string"},
"created_on":{"type":"string"},
"expires_seconds":{"type":"number"}
}};
var jsonData = pm.response.json();
pm.expect(tv4.validate(jsonData,schema)).to.be.true;
});- Werte der zurückgegebenen Daten: Überprüfe, ob die Werte der Antwortdaten plausibel sind; z. B. für nicht-negative Werte:
pm.test("Expires non negative", function() {
pm.expect(pm.response.json().expires_seconds).to.be.above(0);
})- Header-Werte: Überprüfe den Header der Antwort, falls dort nützliche Informationen enthalten sind.
Alle Tests müssen in JavaScript geschrieben werden. Postman wird mit einer eigenen Bibliothek und tv4 für die Schema-Validierung ausgeliefert.
Unten findest du einen vollständig lauffähigen Test:
Einführung in Newman
Wie bereits erwähnt, fungiert Newman als Ausführungsumgebung für das, was in Postman definiert wurde. Um Ergebnisse zu erzeugen, verwendet Newman sogenannte Reporter. Reporter können die Kommandozeile selbst sein, aber auch bekannte Standards wie JUnit sind verfügbar. Der einfachste Weg, Newman zu installieren, ist über NPM (Node Package Manager). Auf DockerHub gibt es einsatzbereite Docker-Images von NodeJS. Installiere das Paket über npm install -g newman.
Es gibt zwei Möglichkeiten, Newman aufzurufen: über die Kommandozeile oder innerhalb von JS-Code. Wir konzentrieren uns hier ausschließlich auf die erste Variante.
Aufruf über die Kommandozeile
Um eine vordefinierte Test-Collection auszuführen, verwende den Befehl newman run. Siehe folgendes Beispiel:
newman run
--reporters cli,junit
--reporter-junit-export /test/out/report.xml
-e /test/env/auth_jwt-docker.pmenv.json
/test/src/auth_jwt-test.pmc.jsonWerfen wir einen genaueren Blick darauf: Erinnere dich daran, dass wir zuvor die Collection und die Environment aus Postman exportiert haben. Die Environment kann mit der Option -e angehängt werden. Zudem wurden zwei Reporter angegeben: die CLI selbst, die ins Terminal schreibt, und junit, die zusätzlich einen Report in die Datei report.xml exportieren soll.
Der CLI-Reporter gibt Folgendes aus (beachte, dass die ersten drei Testfälle aus dem vorgeschlagenen Testschema stammen):
→ jwt-new-token
POST http://tp_auth_jwt:5000/new-token/bot123 [201 CREATED, 523B, 42ms]
✓ Successful POST request
✓ Response has correct schema
✓ Expires non negative
→ jwt-auth
POST http://tp_auth_jwt:5000/new-token/test [201 CREATED, 521B, 11ms]
GET http://tp_auth_jwt:5000/auth [200 OK, 176B, 9ms]
✓ Status code is 200
✓ Login name is correct
→ jwt-auth-no-token
GET http://tp_auth_jwt:5000/auth [401 UNAUTHORIZED, 201B, 9ms]
✓ Status is 401 or 403
→ jwt-auth-bad-token
GET http://tp_auth_jwt:5000/auth [403 FORBIDDEN, 166B, 6ms]
✓ Status is 401 or 403
Integration in Jenkins
Die Funktionalität von Newman kann nun in (fast?) jedes Pipeline-Tool integriert werden. Für Jenkins erstellen wir ein Docker-Image auf Basis von NodeJS mit vorinstalliertem Newman. Anschließend packen oder mounten wir sowohl die Environment- als auch die Collection-Datei in den Docker-Container. Beim Ausführen des Containers verwenden wir Newman als Kommandozeilentool, genauso wie zuvor. Um dies in einer Testphase einer Pipeline zu nutzen, müssen wir sicherstellen, dass die REST-API tatsächlich läuft, wenn Newman ausgeführt wird.
Im folgenden Beispiel wurden die Funktionalitäten als Targets eines Makefiles definiert:
- run zum Starten der REST-API mit allen Abhängigkeiten
- test zum Ausführen des Newman-Containers, der wiederum die Test-Collection ausführt
- rm zum Stoppen und Entfernen der REST-API
Nachdem die API getestet wurde, wird der Report von JUnit mit dem Befehl junit <report> von Jenkins verarbeitet.
Siehe unten einen Pipeline-Ausschnitt eines Testlaufs:
node{
stage('Test'){
try{
sh "cd docker && make run"
sh "sleep 5"
sh "cd docker && make test"
junit "source/test/out/report.xml"
} catch (Exception e){
echo e
} finally {
sh "cd docker && make rm"
}
}
}Zusammenfassung
Jetzt ist es an der Zeit, Tests für deine REST-API zu schreiben. Versuche außerdem, sie in deinen Build-Test-Zyklus und in deine Automatisierungspipeline zu integrieren, denn Automatisierung und definierte Prozesse sind entscheidend, um zuverlässigen Code und stabile Pakete zu liefern. Ich hoffe, dass du mit diesem Blogpost ein besseres Verständnis dafür bekommen hast, wie Postman und Newman genutzt werden können, um ein Test-Framework für REST-APIs umzusetzen. Postman wurde als Definitionstool verwendet, während Newman die Ausführung dieser Definitionen übernimmt. Aufgrund seiner Eigenschaften haben wir auch gesehen, dass Newman das passende Tool für deine Build-Pipeline ist.
Happy coding!
We’re hiring!
Data Engineering ist genau dein Ding und du suchst einen Job? Wir suchen aktuell Junior Consultants und Consultants im Bereich Data Engineering. Die Anforderungen und Vorteile findest du auf unserer Karriereseite. Wir freuen uns auf deine Bewerbung!


