Master R Shiny: Ein Trick zum Aufbau wartbarer und skalierbarer Ereignisketten


Einführung
Ansprechende interaktive Webanwendungen erstellen – eine der vielen Kompetenzen von statworx – ist mit R Shiny ganz einfach. Nur wenige Zeilen Code in einem R-Skript erzeugen die gesamte Logik, die Sie benötigen, um die ganze Magie von Shiny geschehen zu lassen. Es ist so einfach, dass Sie im Handumdrehen eine Hello-World-App erstellen können, einfach so:
library(shiny)
ui <- fluidPage(
"Hello, World!"
)
server <- function(input, output, session) { }
shinyApp(ui, server)
Heute zeige ich Ihnen eine Möglichkeit, wie Sie die native Shiny-Syntax verwenden können, um Teile Ihres Codes zu modularisieren, sodass Ihre Codebasis leicht wartbar und erweiterbar bleibt. Da ich davon ausgehe, dass Sie bereits mit Shiny vertraut sind, überspringe ich das Intro-Beispiel und gehe direkt zum Hauptteil.
Was sind Ereignisketten?
Eine Ereigniskette beschreibt die Beziehung zwischen Ereignissen und Aufgaben und wie die Ereignisse sich gegenseitig beeinflussen. In einigen Fällen möchten Sie möglicherweise eine App haben, die Benutzereingaben entgegennimmt und Aktionen basierend auf der Art der Eingabe ausführt, wobei möglicherweise unterwegs weitere Informationen angefordert werden. In einem solchen Fall möchten Sie möglicherweise eine Ereigniskette implementieren. Sie könnten sofort anfangen, eine grobe Lösung für Ihr Problem zu entwickeln, riskieren jedoch, schwer verständlichen Code zu erstellen. Darüber hinaus stellen Sie sich vor, dass sich die Anforderungen an Ihre Ereigniskette plötzlich ändern. In diesem Fall ist es wichtig, Ihre Ereigniskette zu modularisieren, damit sie wartbar und anpassbar bleibt.
Beispiel: der Freund-Logger
Lassen Sie mich veranschaulichen, wie man eine modularisierte Ereigniskette aufbaut. Stellen Sie sich vor, Sie sind pedantisch in Bezug auf Zeit und nehmen Termine ernst. Zum Nachteil Ihrer sogenannten „Freunde“ machen Sie keine Ausnahmen. Jedes Mal, wenn ein Freund zu spät kommt, leiden Sie so sehr, dass Sie sich entschieden haben, eine Shiny-App zu verwenden, um die Besuche Ihrer Freunde zu protokollieren, um festzustellen, wie zuverlässig sie sind (wie erbärmlich!). Die Anforderungen an die Nutzung der App sind einfach, wie im folgenden Diagramm gezeigt.

Sie möchten die erwartete Ankunftszeit Ihres Freundes mit seiner tatsächlichen Ankunftszeit vergleichen. Wenn seine Verspätung einen bestimmten Schwellenwert überschreitet (z.B. 5 Minuten), möchten Sie seine Entschuldigung für die Verspätung protokollieren. Wenn Sie seine Entschuldigung als akzeptabel erachten, vernachlässigen Sie seine Sünde (aber führen dennoch Protokoll!). Wenn er pünktlich ist, erhält er einen Bonuspunkt. Wenn er zu spät kommt und seine Entschuldigung nicht akzeptabel ist, erhält er einen Minuspunkt. In jedem Fall protokollieren Sie seinen Besuch (wie tief kann man sinken?). Um die Dinge visueller zu gestalten, hier eine Skizze der Benutzeroberfläche der App einschließlich der Ereignissequenz, wenn ein Freund zu spät kommt.
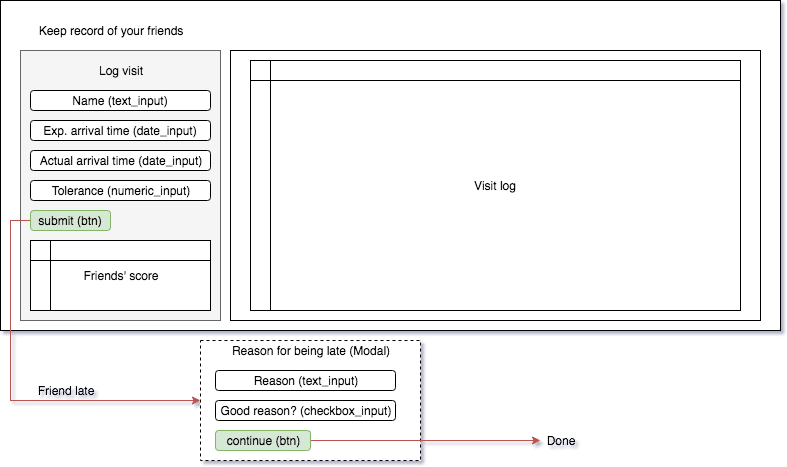
Jetzt ist es an der Zeit, die App zu implementieren.
Ereigniskettenarchitektur in R Shiny
Es braucht zwei Zutaten, um Ereignisketten zu implementieren:
- Auslöser, die in reactiveValues() gespeichert werden
- Beobachter (observeEvent()), die ausgelöst werden und die tatsächlichen Prüfungen und anderen Berechnungen durchführen
Der eigentliche Trick besteht darin, die geeignete Anzahl von observeEvent()s zu finden, sodass jeder Schritt in der Ereigniskette von einem observeEvent abgedeckt wird und daher keine Code-Redundanzen entstehen. Anhand des obigen Beispiels haben wir drei mögliche Ereignissequenzen:
- Freund ist zu spät und hat eine gute Entschuldigung
- Freund ist zu spät und hat keine gute Entschuldigung
- Freund ist nicht zu spät
In allen drei Fällen müssen wir den Besuch eines Freundes protokollieren, daher macht es definitiv Sinn, den Teil der Besuchsprotokollierung in ein observeEvent zu setzen und diesen Beobachter am Ende jeder der oben genannten Sequenzen aufzurufen. Das Zeichnen eines Ereigniskettendiagramms ist hierbei besonders hilfreich, da es eine geeignete architektonische Designentscheidung unterstützt. Ich habe draw.io für diese Aufgabe verwendet.
Für die App habe ich ein reactiveValues-Objekt verwendet, in dem ich alle Auslöser platziert habe (den gesamten App-Code finden Sie auf GitHub).
shinyServer(function(input, output, session) {
# Data
rv <- reactiveValues(
...
# Triggers
ask_for_reason = TRUE,
change_friend_score = TRUE,
save_visit = TRUE,
error = FALSE
)
...
})
Ich verwende boolesche Werte für die Auslöser, sodass ich sie nur negieren muss, wenn ich ihren Wert ändern möchte (a <- !a). Die Verwendung von Ganzzahlen würde ebenfalls funktionieren, aber ich finde den Flip-Trick schöner. Betrachten wir den Teil der Kette, in dem die Pünktlichkeit eines Freundes genauer überprüft wird. Das Modul, das die Pünktlichkeit überprüft, liest auch die Daten ein. Abhängig von der Eingabe ruft es entweder das „Ask-for-a-reason“-Modul auf oder ruft direkt das Visit-Logger-Modul auf.
# Submit friend data ----
observeEvent(input(dollar sign)submit, {
# Collect data
...
is_delayed <- difftime(actual_time, expected_time, units = "mins") > input(dollar sign)acceptance
if (is_delayed) {
# Friend is delayed --> trigger Ask-for-reason-module
rv(dollar sign)ask_for_reason <- isolate(!rv(dollar sign)ask_for_reason)
return()
}
# Friend seems punctual --> Add a point to score list :)
friend_data <- set_data(friend_data, score = 1)
# Trigger visit logger
rv(dollar sign)change_friend_score <- isolate(!rv(dollar sign)change_friend_score)
})
Wie Sie sehen, ist es ziemlich intuitiv, die Ereigniskette in Shiny-Code zu übersetzen, sobald Sie sie gezeichnet haben. Wenn der Freund pünktlich ist, setzen wir seine Bewertung auf eins (die Bewertung wird im Visit-Logger-Modul hinzugefügt) und rufen das Visit-Logger-Modul auf, das folgendermaßen aussieht:
# Change friend score ----
observeEvent(rv(dollar sign)change_friend_score, ignoreInit = TRUE, {
rv(dollar sign)friend_score[friend_score(dollar sign)name == friend_data(dollar sign)name, "score"] <-
isolate(rv(dollar sign)friend_score[friend_score(dollar sign)name == friend_data(dollar sign)name, "score"]) +
friend_data(dollar sign)score
# Make change permanent
saveRDS(rv(dollar sign)friend_score, "data/friend_score.RDS")
rv(dollar sign)save_visit <- isolate(!rv(dollar sign)save_visit)
})
Note that the rv(dollar sign)save_visit trigger simply calls an observer that adds another row to the friend visit table and does some cleaning.
Machen wir nun einen kleinen Testlauf mit dem fertigen Produkt. Damit Ihre App funktioniert, müssen Sie natürlich zuerst einen initialen Datensatz mit Ihren Freunden und ihren Anfangsbewertungen erstellen, um zu wissen, wen Sie aufzeichnen. Im Beispiel unten haben wir vier Freunde: John, Emily, Olivia und Ethan. Sie können ihre Bewertungen in der unteren linken Ecke sehen. Vergangene Besuche werden protokolliert und in der oberen rechten Ecke angezeigt.

John möchte mit uns abhängen, um brutale Videospiele zu spielen, und aus keinem offensichtlichen Grund haben wir um 9 Uhr morgens einen Termin gemacht. John kommt jedoch 7 (!!!) Minuten zu spät. Genug ist genug. Wir tragen seine Missetat ein.

Sie überschreitet den Schwellenwert, sodass wir erwartungsgemäß aufgefordert werden, den Grund einzutragen.

Als wir John um eine Rechtfertigung baten, zuckte er nur mit den Schultern. Wie kann er es wagen?! Das ist ein Minuspunkt…
Unsere Ereigniskette erweitern
Obwohl Sie wegen Johns Unzuverlässigkeit verletzt sind, sind Sie mit Ihrer App ziemlich zufrieden. Doch die Dinge könnten besser sein! Zum Beispiel stürzt Ihre App jedes Mal ab, wenn Sie einen Freund im Namensfeld falsch schreiben, wenn Sie einen Besuch protokollieren. Ihre App könnte einige (zusätzliche) Plausibilitätsprüfungen verwenden. Ein perfekter Anwendungsfall, um die Flexibilität Ihrer Architektur zu zeigen. Nach einigen Monaten der tiefen Reflexion haben Sie ein neues Ereignisablaufdiagramm entwickelt, das sich um falsche Eingaben kümmert.
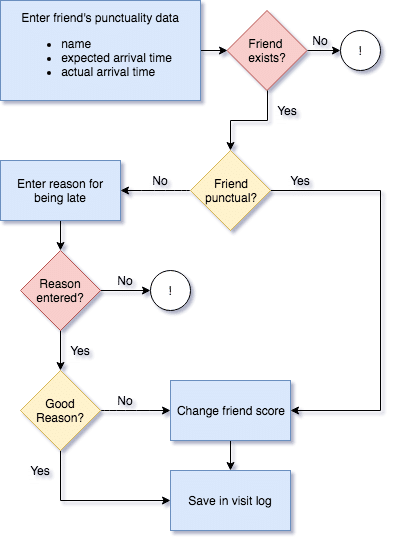
Sie haben zwei Stellen identifiziert, an denen die App stabilisiert werden sollte. Erstens möchten Sie einen Fehler an den Benutzer ausgeben, wenn ein Freund nicht existiert (ohne die App zu stoppen). Zweitens erfordern Sie von sich selbst, einen Grund einzugeben (wir wissen alle, wie nachlässig unser zukünftiges Selbst manchmal sein kann).
Mit der bereits gewählten modularisierten Struktur ist es einfach, diese Prüfungen zu integrieren. Sie müssen lediglich einen weiteren Auslöser hinzufügen (rv(dollar sign)error) und einen globalen Container, der die Fehlerinformationen speichert.
# Error handler
error <- reactiveValues(
title = "",
message = ""
)
Wenn Sie beispielsweise überprüfen möchten, ob ein eingegebener Name in Ihrer Datenbank existiert, müssen Sie nur ein paar Codezeilen am Anfang des Beobachters hinzufügen, in dem die Pünktlichkeit eines Freundes überprüft wird.
# Submit friend data ----
observeEvent(input(dollar sign)submit, {
# Friend exists?
if (!input(dollar sign)name %in% rv(dollar sign)friend_score(dollar sign)name) {
error(dollar sign)title <- "%s not found" %>% sprintf(., input(dollar sign)name)
error(dollar sign)message <- h1("404")
rv(dollar sign)error <- isolate(!rv(dollar sign)error)
return()
}
...
})
Wenn der Name nicht mit einem Ihrer Freundesnamen übereinstimmt, lösen Sie ein Fehlerbehandlungsmodul aus, dessen einziger Zweck darin besteht, eine Fehlermeldung anzuzeigen:
# Error handling ----
observeEvent(rv(dollar sign)error, ignoreInit = TRUE, {
showModal(modalDialog(
title = error(dollar sign)title,
error(dollar sign)message,
footer = actionButton("exit", "Ok", class = "btn-primary")
))
})
Das Schöne daran ist, dass Sie dieses Modul verwenden können, um jegliche Fehler zu behandeln, unabhängig davon, welche Plausibilitätsprüfungen sie verursacht haben.
Wenn wir nun zur App zurückkehren und einen Namen eingeben, der nicht existiert (wie Tobias), erhalten wir folgende Fehlermeldung:

Darüber hinaus erhalten wir eine passiv-aggressive Erinnerung, wenn wir keinen Grund eingeben, wenn wir dazu aufgefordert werden:

Bitte sehr! Würden Sie mich jetzt entschuldigen? Ich habe einige Besuche zu protokollieren…


