Einstieg in Flexdashboards in R


Einführung
Hier bei statworx legen wir Wert auf leserfreundliche Präsentationen unserer Arbeit. Für viele R-Nutzer:innen besteht die Wahl normalerweise zwischen einer Markdown-Datei, die ein .html- oder .pdf-Dokument erzeugt, oder einer Shiny-Anwendung, die den Nutzer:innen ein leicht navigierbares Dashboard bietet.
Was, wenn du eine Dashboard-artige Präsentation ohne großen Aufwand erstellen möchtest? Dann bist du hier richtig. Das R Studio-Paket flexdashboard bietet Data Scientists eine Markdown-basierte Möglichkeit, Dashboards einfach einzurichten, ohne auf vollständige Frontend-Entwicklung zurückgreifen zu müssen. Die Verwendung von Shiny kann etwas zu aufwendig sein, wenn das Ziel darin besteht, deine Arbeit in einem Dashboard zu präsentieren.
Warum solltest du dich über Flexdashboards informieren? Wenn du mit R Markdown vertraut bist und ein wenig über Shiny weißt, sind Flexdashboards einfach zu erlernen und bieten dir eine Alternative zu Shiny-Dashboards.
In diesem Beitrag lernst du die Grundlagen zur Gestaltung eines Flexdashboards kennen. Am Ende dieses Artikels wirst du in der Lage sein:
- ein einfaches Dashboard mit mehreren Seiten zu erstellen
- Tabs auf jeder Seite zu platzieren und das Layout anzupassen
- Widgets zu integrieren
- dein Shiny-Dokument auf ShinyApps.io bereitzustellen.
Die basic Regeln
Um ein Flexdashboard einzurichten, installiere das Paket von CRAN mit dem Standardbefehl. Um zu beginnen, gib Folgendes in die Konsole ein:
rmarkdown::draft(file = "my_dashboard", template = "flex_dashboard", package = "flexdashboard")
Diese Funktion erstellt eine .Rmd-Datei mit dem zugeordneten Dateinamen und verwendet das Flexdashboard-Template des Pakets. Beim Rendern deines neu erstellten Dashboards erhältst du ein spaltenorientiertes Layout mit einem Header, einer Seite und drei Boxen. Standardmäßig ist die Seite in Spalten unterteilt, und die linke Spalte ist doppelt so hoch wie die beiden rechten Boxen.
Du kannst die Layout-Orientierung auf Zeilen umstellen und auch ein anderes Thema auswählen. Das Hinzufügen von runtime: shiny zum YAML-Header ermöglicht die Verwendung von HTML-Widgets.
Jede Zeile (oder Spalte) wird mit dem ——— Header erstellt, und die Panels selbst werden mit einem ### Header gefolgt vom Titel des Panels erstellt. Du kannst für jede Zeile eine Tab-Einstellung einführen, indem du das {.tabset}-Attribut nach seinem Namen hinzufügst. Um eine Seite hinzuzufügen, verwende den (=======) Header und setze den Seitennamen darüber. Die Zeilenhöhe kann durch die Verwendung von {.data-height = } nach einem Zeilennamen geändert werden, wenn du ein zeilenorientiertes Layout gewählt hast. Je nach Layout kann es sinnvoll sein, stattdessen {.data-width = } zu verwenden.
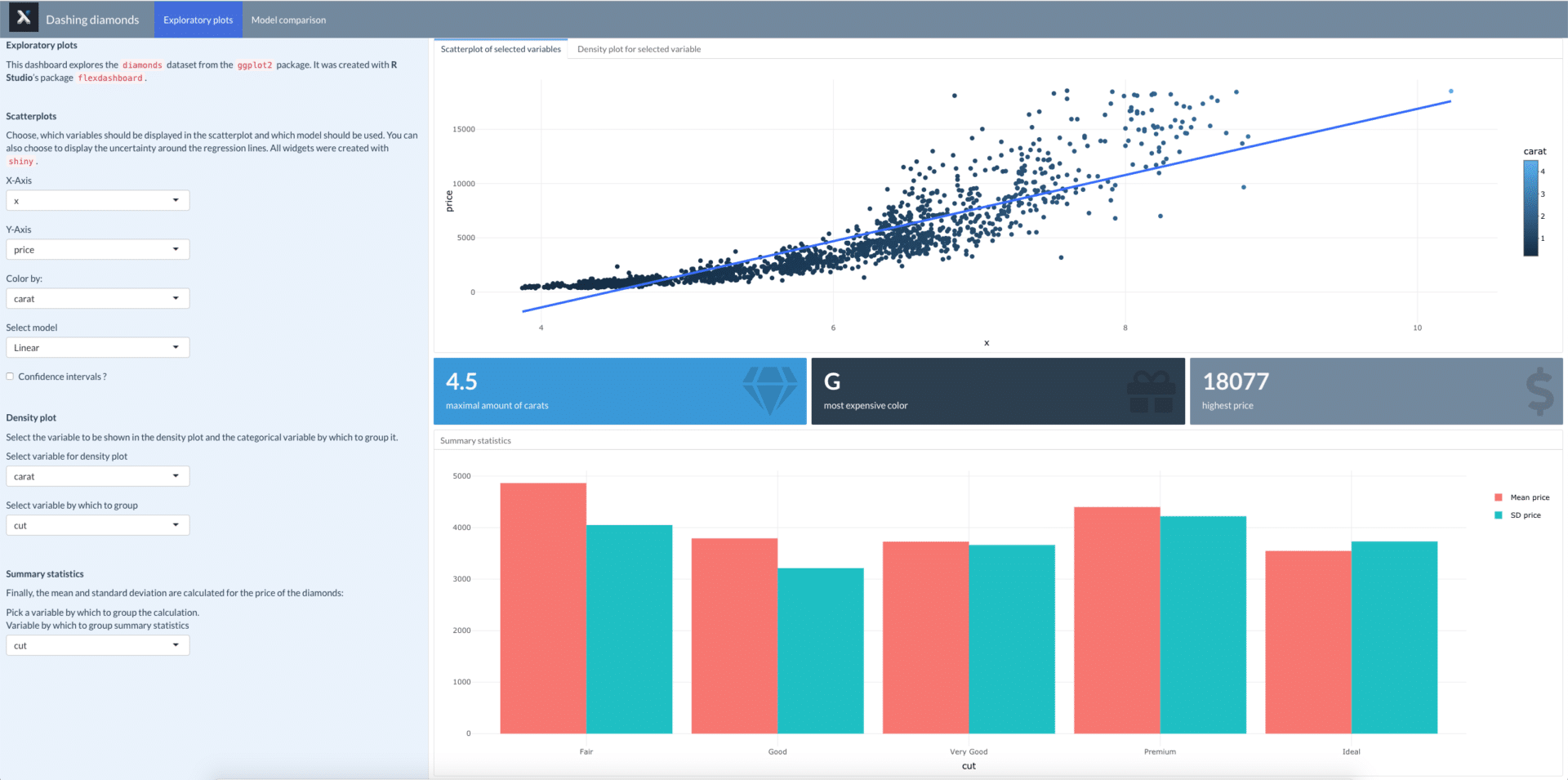
Hier entwerfe ich ein Dashboard, das den berühmten Diamanten-Datensatz untersucht, den man im ggplot2-Paket findet. Während die erste Seite einige explorative Plots enthält, vergleicht die zweite Seite die Leistung eines linearen Modells und einer Ridge-Regression bei der Vorhersage des Preises.
Dies ist das Gerüst des Dashboards (ohne R-Code und beschreibenden Text):
---
title: "Dashing diamonds"
output:
flexdashboard::flex_dashboard:
orientation: rows
vertical_layout: fill
css: bootswatch-3.3.5-4/flatly/bootstrap.css
logo: STATWORX_2.jpg
runtime: shiny
---
Exploratory plots
=======================================================================
Sidebar {.sidebar data-width=700}
-----------------------------------------------------------------------
**Exploratory plots**
<br>
**Scatterplots**
<br>
**Density plot**
<br>
**Summary statistics**
<br>
Row {.tabset}
-----------------------------------------------------------------------
### Scatterplot of selected variables
### Density plot for selected variable
Row
-----------------------------------------------------------------------
### Maximum carats {data-width=50}
### Most expensive color {data-width=50}
### Maximal price {data-width=50}
Row {data-height=500}
-----------------------------------------------------------------------
### Summary statistics {data-width=500}
Model comparison
=======================================================================
Sidebar {.sidebar data-width=700}
-----------------------------------------------------------------------
**Model comparison**
<br>
Row{.tabset}
-----------------------------------------------------------------------
**Comparison of Predictions and Target**
### Linear Model
### Ridge Regression
Row
-----------------------------------------------------------------------
### Densities of predictions vs. target
Die Seitenleisten wurden hinzugefügt, indem das Attribut {.sidebar} nach dem Namen, gefolgt von einem Seiten- oder Zeilenheader, angegeben wurde. Seiten-Header (========) erstellen globale Seitenleisten, während lokale Seitenleisten mit Zeilen-Headern (---------) erstellt werden. Wenn du eine globale Seitenleiste wählst, erscheint sie auf allen Seiten, während eine lokale Seitenleiste nur auf der Seite erscheint, auf der sie platziert ist. Im Allgemeinen ist es eine gute Idee, die Seitenleiste nach dem Anfang der Seite und vor der ersten Zeile der Seite hinzuzufügen. Seitenleisten sind auch gut geeignet, um Beschreibungen darüber hinzuzufügen, worum es bei deinem Dashboard/deiner Anwendung geht. Hier habe ich auch die Breite mit dem Attribut data-width geändert. Das verbreitert die Seitenleiste und erleichtert das Lesen der Beschreibung. Du kannst auch Ausgaben in deiner Seitenleiste anzeigen, indem du Code-Schnipsel darunter hinzufügst.
Interaktive Widgets hinzufügen
Da das Grundlayout nun fertig ist, fügen wir etwas Interaktivität hinzu. Unter der Beschreibung in der Seitenleiste auf der ersten Seite habe ich mehrere Widgets hinzugefügt.
```{r}
selectInput("x", "X-Axis", choices = names(train_df), selected = "x")
selectInput("y", "Y-Axis", choices = names(train_df), selected = "price")
selectInput("z", "Color by:", choices = names(train_df), selected = "carat")
selectInput("model_type", "Select model", choices = c("LOESS" = "loess", "Linear" = "lm"), selected = "lm")
checkboxInput("se", "Confidence intervals ?")
```
Beachte, dass die Widgets identisch sind mit denen, die du normalerweise in einer Shiny-Anwendung findest, und sie funktionieren, weil runtime: shiny im YAML angegeben ist.
Um die Plots auf Änderungen in der Datumsauswahl reagieren zu lassen, musst du die Eingabe-IDs deiner Widgets innerhalb der entsprechenden Render-Funktion angeben. Zum Beispiel wird der Scatterplot als Plotly-Ausgabe gerendert:
```{r}
renderPlotly({
p <- train_df %>%
ggplot(aes_string(x = input$x, y = input$y, col = input$z)) +
geom_point() +
theme_minimal() +
geom_smooth(method = input$model_type, position = "identity", se = input$se) +
labs(x = input$x, y = input$y)
p %>% ggplotly()
})
```
Du kannst die Render-Funktionen verwenden, die du auch in einer Shiny-Anwendung verwenden würdest. Natürlich musst du keine Render-Funktionen verwenden, um Grafiken anzuzeigen, aber sie haben den Vorteil, dass sie die Plots neu skalieren, wenn das Browserfenster neu dimensioniert wird.
Wertboxen hinzufügen
Neben Plots und Tabellen sind Wertboxen eine der stilvolleren Funktionen von Dashboards. Flexdashboard bietet eine eigene Funktion für Wertboxen, mit denen du Informationen über wichtige Indikatoren, die für deine Arbeit relevant sind, schön darstellen kannst. Hier werde ich drei solche Boxen hinzufügen, die den maximalen Preis, die teuerste Farbe von Diamanten und die maximale Menge an Karat im Datensatz anzeigen.
flexdashboard::valueBox(max(train_df$carat),
caption = "maximal amount of carats",
color = "info",
icon = "fa-gem")
Es gibt mehrere Quellen, aus denen Icons bezogen werden können. In diesem Beispiel habe ich das Edelstein-Icon von Font Awesome verwendet. Dieses Code-Schnipsel folgt einem Header, der ansonsten für einen Plot oder eine Tabelle verwendet würde, d.h. einem ### Header.
Letzte Feinheiten und Bereitstellung
Um dein Dashboard abzuschließen, kannst du ein Logo hinzufügen und aus einem der mehreren Themen wählen oder eine CSS-Datei anhängen. Hier habe ich ein Bootswatch-Theme hinzugefügt und die Farben leicht modifiziert. Die meisten Themen erfordern, dass das Logo 48×48 Pixel groß ist.
---
title: "Dashing diamonds"
output:
flexdashboard::flex_dashboard:
orientation: rows
vertical_layout: fill
css: bootswatch-3.3.5-4/flatly/bootstrap.css
logo: STATWORX_2.jpg
runtime: shiny
---
Nachdem du dein Dashboard mit runtime: shiny erstellt hast, kann es auf ShinyApps.io gehostet werden, vorausgesetzt, du hast ein Konto. Du musst auch das Paket rsconnect installieren. Das Dokument kann mit der ‘publish to server’ Funktion in RStudio oder mit:
rsconnect::deployDoc('path')
Du kannst diese Funktion verwenden, nachdem du dein Konto erhalten und es mit rsconnect::setAccountInfo() unter Verwendung eines Zugangstokens und eines Geheimnisses, das von der Website bereitgestellt wird, autorisiert hast. Stelle sicher, dass alle notwendigen Dateien Teil desselben Ordners sind. RStudios Veröffentlichung auf dem Server hat den Vorteil, dass es automatisch die externen Dateien erkennt, die deine Anwendung benötigt. Du kannst das Beispiel-Dashboard hier ansehen und den Code auf unserer GitHub-Seite finden.
Zusammenfassung
In diesem Beitrag hast du gelernt, wie du ein Flexdashboard einrichtest, anpasst und bereitstellst – alles ohne JavaScript oder CSS zu kennen, oder sogar viel R Shiny. Allerdings ist das, was du hier gelernt hast, nur der Anfang! Dieses mächtige Paket ermöglicht es dir auch, Storyboards zu erstellen, sie auf eine modularere Weise mit R Shiny zu integrieren und sogar Dashboards für mobile Geräte einzurichten. Wir werden diese Themen gemeinsam in zukünftigen Beiträgen erkunden. Bleib dran!


